Dokumentation Profiimport¶
Note
18.12.2024 Version 1
gegebener Code aus zip Dateie die wir heruntergeladen haben:
--- Sample employee database
-- See changelog table for details
-- Copyright (C) 2007,2008, MySQL AB
--
-- Original data created by Fusheng Wang and Carlo Zaniolo
-- http://www.cs.aau.dk/TimeCenter/software.htm
-- http://www.cs.aau.dk/TimeCenter/Data/employeeTemporalDataSet.zip
--
-- Current schema by Giuseppe Maxia
-- Data conversion from XML to relational by Patrick Crews
--
-- This work is licensed under the
-- Creative Commons Attribution-Share Alike 3.0 Unported License.
-- To view a copy of this license, visit
-- http://creativecommons.org/licenses/by-sa/3.0/ or send a letter to
-- Creative Commons, 171 Second Street, Suite 300, San Francisco,
-- California, 94105, USA.
--
-- DISCLAIMER
-- To the best of our knowledge, this data is fabricated, and
-- it does not correspond to real people.
-- Any similarity to existing people is purely coincidental.
--
USE employees;
SELECT 'TESTING INSTALLATION' as 'INFO';
DROP TABLE IF EXISTS expected_values, found_values;
CREATE TABLE expected_values (
table_name varchar(30) not null primary key,
recs int not null,
crc_sha varchar(100) not null,
crc_md5 varchar(100) not null
);
CREATE TABLE found_values LIKE expected_values;
INSERT INTO `expected_values` VALUES
('employees', 300024,'4d4aa689914d8fd41db7e45c2168e7dcb9697359',
'4ec56ab5ba37218d187cf6ab09ce1aa1'),
('departments', 9,'4b315afa0e35ca6649df897b958345bcb3d2b764',
'd1af5e170d2d1591d776d5638d71fc5f'),
('dept_manager', 24,'9687a7d6f93ca8847388a42a6d8d93982a841c6c',
'8720e2f0853ac9096b689c14664f847e'),
('dept_emp', 331603, 'd95ab9fe07df0865f592574b3b33b9c741d9fd1b',
'ccf6fe516f990bdaa49713fc478701b7'),
('titles', 443308,'d12d5f746b88f07e69b9e36675b6067abb01b60e',
'bfa016c472df68e70a03facafa1bc0a8'),
('salaries', 2844047,'b5a1785c27d75e33a4173aaa22ccf41ebd7d4a9f',
'fd220654e95aea1b169624ffe3fca934');
SELECT table_name, recs AS expected_records, crc_md5 AS expected_crc FROM expected_values;
DROP TABLE IF EXISTS tchecksum;
CREATE TABLE tchecksum (chk char(100));
SET @crc= '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc,
emp_no,birth_date,first_name,last_name,gender,hire_date))
FROM employees ORDER BY emp_no;
INSERT INTO found_values VALUES ('employees', (SELECT COUNT(*) FROM employees), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, dept_no,dept_name))
FROM departments ORDER BY dept_no;
INSERT INTO found_values values ('departments', (SELECT COUNT(*) FROM departments), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, dept_no,emp_no, from_date,to_date))
FROM dept_manager ORDER BY dept_no,emp_no;
INSERT INTO found_values values ('dept_manager', (SELECT COUNT(*) FROM dept_manager), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, dept_no,emp_no, from_date,to_date))
FROM dept_emp ORDER BY dept_no,emp_no;
INSERT INTO found_values values ('dept_emp', (SELECT COUNT(*) FROM dept_emp), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, emp_no, title, from_date,to_date))
FROM titles order by emp_no,title,from_date;
INSERT INTO found_values values ('titles', (SELECT COUNT(*) FROM titles), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, emp_no, salary, from_date,to_date))
FROM salaries order by emp_no,from_date,to_date;
INSERT INTO found_values values ('salaries', (SELECT COUNT(*) FROM salaries), @crc,@crc);
DROP TABLE tchecksum;
SELECT table_name, recs as 'found_records ', crc_md5 as found_crc from found_values;
SELECT
e.table_name,
IF(e.recs=f.recs,'OK', 'not ok') AS records_match,
IF(e.crc_md5=f.crc_md5,'ok','not ok') AS crc_match
from
expected_values e INNER JOIN found_values f USING (table_name);
set @crc_fail=(select count(*) from expected_values e inner join found_values f on (e.table_name=f.table_name) where f.crc_md5 != e.crc_md5);
set @count_fail=(select count(*) from expected_values e inner join found_values f on (e.table_name=f.table_name) where f.recs != e.recs);
select timediff(
now(),
(select create_time from information_schema.tables where table_schema='employees' and table_name='expected_values')
) as computation_time;
DROP TABLE expected_values,found_values;
select 'CRC' as summary, if(@crc_fail = 0, "OK", "FAIL" ) as 'result'
union all
select 'count', if(@count_fail = 0, "OK", "FAIL" );
wir haben denn Code dann Chat-GPT gegeben um uns Kommentare hinzufügen zu lassen wie es funktioniert und haben dann folgende Ausgabe erhalten:
-- Wechselt in die 'employees'-Datenbank
USE employees;
-- Zeigt eine Nachricht an, dass die Installation getestet wird
SELECT 'TESTING INSTALLATION' as 'INFO';
-- Löscht eventuell bestehende Tabellen 'expected_values' und 'found_values'
DROP TABLE IF EXISTS expected_values, found_values;
-- Erstellt eine Tabelle 'expected_values', die die erwarteten Daten enthält (Tabellenname, Anzahl der Datensätze, und CRC-Prüfziffern)
CREATE TABLE expected_values (
table_name varchar(30) not null primary key, -- Name der Tabelle
recs int not null, -- Erwartete Anzahl der Datensätze
crc_sha varchar(100) not null, -- SHA-Hash als Prüfziffer (Prüfziffer für die Daten)
crc_md5 varchar(100) not null -- MD5-Hash als alternative Prüfziffer
);
-- Erstellt eine Tabelle 'found_values', die ähnliche Struktur wie 'expected_values' hat
CREATE TABLE found_values LIKE expected_values;
-- Fügt die erwarteten Werte für jede Tabelle in die 'expected_values'-Tabelle ein
-- Diese Werte sind die Anzahl der Datensätze und die CRC-Werte (Prüfziffern), die als korrekt angenommen werden
INSERT INTO `expected_values` VALUES
('employees', 300024,'4d4aa689914d8fd41db7e45c2168e7dcb9697359', '4ec56ab5ba37218d187cf6ab09ce1aa1'),
('departments', 9,'4b315afa0e35ca6649df897b958345bcb3d2b764','d1af5e170d2d1591d776d5638d71fc5f'),
('dept_manager', 24,'9687a7d6f93ca8847388a42a6d8d93982a841c6c','8720e2f0853ac9096b689c14664f847e'),
('dept_emp', 331603, 'd95ab9fe07df0865f592574b3b33b9c741d9fd1b','ccf6fe516f990bdaa49713fc478701b7'),
('titles', 443308,'d12d5f746b88f07e69b9e36675b6067abb01b60e','bfa016c472df68e70a03facafa1bc0a8'),
('salaries', 2844047,'b5a1785c27d75e33a4173aaa22ccf41ebd7d4a9f','fd220654e95aea1b169624ffe3fca934');
-- Zeigt die erwarteten Werte (Tabellenname, Anzahl der Datensätze und CRC-Werte) aus der Tabelle 'expected_values' an
SELECT table_name, recs AS expected_records, crc_md5 AS expected_crc FROM expected_values;
-- Erstellt eine temporäre Tabelle 'tchecksum' zur Berechnung der CRC-Werte der tatsächlichen Daten
DROP TABLE IF EXISTS tchecksum;
CREATE TABLE tchecksum (chk char(100));
-- Berechnet die CRC-Prüfziffer für die Tabelle 'employees' und speichert sie in 'found_values'
SET @crc= ''; -- Initialisiert eine leere Variable für die Prüfziffer
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, emp_no,birth_date,first_name,last_name,gender,hire_date))
FROM employees ORDER BY emp_no; -- Berechnet den MD5-Hash für alle Daten in 'employees'
INSERT INTO found_values VALUES ('employees', (SELECT COUNT(*) FROM employees), @crc,@crc);
-- Wiederholt die CRC-Berechnung und Speicherung für andere Tabellen:
-- Für 'departments', 'dept_manager', 'dept_emp', 'titles' und 'salaries'
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, dept_no,dept_name))
FROM departments ORDER BY dept_no;
INSERT INTO found_values values ('departments', (SELECT COUNT(*) FROM departments), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, dept_no,emp_no, from_date,to_date))
FROM dept_manager ORDER BY dept_no,emp_no;
INSERT INTO found_values values ('dept_manager', (SELECT COUNT(*) FROM dept_manager), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, dept_no,emp_no, from_date,to_date))
FROM dept_emp ORDER BY dept_no,emp_no;
INSERT INTO found_values values ('dept_emp', (SELECT COUNT(*) FROM dept_emp), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, emp_no, title, from_date,to_date))
FROM titles order by emp_no,title,from_date;
INSERT INTO found_values values ('titles', (SELECT COUNT(*) FROM titles), @crc,@crc);
SET @crc = '';
INSERT INTO tchecksum
SELECT @crc := MD5(CONCAT_WS('#',@crc, emp_no, salary, from_date,to_date))
FROM salaries order by emp_no,from_date,to_date;
INSERT INTO found_values values ('salaries', (SELECT COUNT(*) FROM salaries), @crc,@crc);
-- Löscht die temporäre Tabelle 'tchecksum', da die CRC-Berechnung abgeschlossen ist
DROP TABLE tchecksum;
-- Zeigt die tatsächlichen gefundenen Werte (Anzahl der Datensätze und CRC-Werte) an
SELECT table_name, recs as 'found_records ', crc_md5 as found_crc from found_values;
-- Vergleicht die erwarteten und gefundenen Werte (Anzahl der Datensätze und CRC-Prüfziffern)
SELECT
e.table_name,
IF(e.recs=f.recs,'OK', 'not ok') AS records_match, -- Vergleicht die Anzahl der Datensätze
IF(e.crc_md5=f.crc_md5,'ok','not ok') AS crc_match -- Vergleicht die CRC-Werte
FROM
expected_values e INNER JOIN found_values f USING (table_name);
-- Zählt, wie viele Fehler bei den CRC-Werten und der Datensatzanzahl gefunden wurden
set @crc_fail=(select count(*) from expected_values e inner join found_values f on (e.table_name=f.table_name) where f.crc_md5 != e.crc_md5);
set @count_fail=(select count(*) from expected_values e inner join found_values f on (e.table_name=f.table_name) where f.recs != e.recs);
-- Berechnet die Zeit, die für die Berechnung der Prüfziffern benötigt wurde
select timediff(
now(),
(select create_time from information_schema.tables where table_schema='employees' and table_name='expected_values')
) as computation_time;
-- Löscht die Tabellen 'expected_values' und 'found_values' nach Abschluss der Prüfung
DROP TABLE expected_values,found_values;
-- Zeigt das Ergebnis der Überprüfung (ob CRC und Datensatzanzahl übereinstimmen) an
select 'CRC' as summary, if(@crc_fail = 0, "OK", "FAIL" ) as 'result'
union all
select 'count', if(@count_fail = 0, "OK", "FAIL" );
Zusammenfassung für Laien:¶
- Ziel: Dieser Code überprüft, ob die Daten in der
employees-Datenbank korrekt und unverändert sind. - Prüfziffern (CRC): Für jede Tabelle werden spezielle Prüfziffern (CRC) berechnet. Diese dienen als eine Art "Fingerabdruck" der Daten, um sicherzustellen, dass die Daten seit einer bestimmten Referenzzeit nicht verändert wurden.
- Ergebnisse: Der Code vergleicht dann, ob die berechneten CRC-Werte und die Anzahl der Datensätze mit den erwarteten Werten übereinstimmen. Am Ende zeigt er an, ob alles korrekt ist oder ob Fehler gefunden wurden.
- Zusätzliche Informationen: Der Code misst auch die Zeit, die für diese Überprüfung benötigt wurde.
Im Wesentlichen handelt es sich um eine Datenintegritätsprüfung, die sicherstellt, dass die Daten in der Datenbank unverändert sind.
Doku Friendzone Privileges¶
Aufgabe:
Ziel dieses Arbeitsauftrags ist es, eine praxisorientierte und funktionierende User- und Gruppenverwaltung für die "Friendzone"-Datenbank zu erstellen. Sie werden Benutzer und Gruppen anlegen, Berechtigungen zuweisen und sicherstellen, dass die Datenbank sicher und effizient verwaltet werden kann.
Analyse der Anforderungen¶
- Überlegen Sie, welche Benutzerrollen und -gruppen in der "Friendzone" benötigt werden könnten. Typische Rollen könnten Administratoren, Moderatoren und normale Benutzer sein.
- Definieren Sie die Aufgaben und Verantwortlichkeiten jeder Rolle in Bezug auf den Datenbankzugriff.
Erstellung von Benutzergruppen¶
- Legen Sie Gruppen in der Datenbank an, die verschiedene Berechtigungsstufen repräsentieren. Vorschläge:
- Admin: Vollzugriff auf alle Tabellen und Funktionen.
- Moderator: Zugriff auf Tabellen wie
comments,photos,userszur Moderation von Inhalten. - User: Eingeschränkter Zugriff, hauptsächlich auf eigene Daten in
photos,comments.
Anlegen von Benutzern¶
- Erstellen Sie Benutzerkonten für die verschiedenen Rollen. Beispiel:
CREATE USER 'admin_user'@'localhost' IDENTIFIED BY 'securepassword';
CREATE USER 'moderator_user'@'localhost' IDENTIFIED BY 'securepassword';
CREATE USER 'normal_user'@'localhost' IDENTIFIED BY 'securepassword';
Zuweisung von Berechtigungen¶
- Weisen Sie den Benutzern die entsprechenden Berechtigungen zu. Beispiel:
Admin:
Moderator:
GRANT SELECT, INSERT, UPDATE, DELETE ON friendzone.comments TO 'moderator_user'@'localhost';
GRANT SELECT, INSERT, UPDATE, DELETE ON friendzone.photos TO 'moderator_user'@'localhost';
GRANT SELECT ON friendzone.users TO 'moderator_user'@'localhost';
User:
GRANT SELECT, INSERT, UPDATE ON friendzone.photos TO 'normal_user'@'localhost';
GRANT SELECT, INSERT ON friendzone.comments TO 'normal_user'@'localhost';
| Role | Table | Privileges | User |
|---|---|---|---|
| Owner | All Tables | ALL PRIVILEGES | owner_user |
| Admin | comments | SELECT, INSERT, UPDATE, DELETE | admin_user |
| photos | SELECT, INSERT, UPDATE, DELETE | admin_user | |
| users | SELECT, UPDATE, DELETE | admin_user | |
| Moderator | comments | SELECT, INSERT, UPDATE, DELETE | moderator_user |
| photos | SELECT, INSERT, UPDATE, DELETE | moderator_user | |
| users | SELECT | moderator_user | |
| User | photos | SELECT, INSERT, UPDATE | normal_user |
| comments | SELECT, INSERT | normal_user | |
| Guest | comments | SELECT | guest_user |
| photos | SELECT | guest_user | |
| users | SELECT | guest_user |
Owner:¶
- Rechte: Hat ALLE Privilegien auf alle Tabellen. Der Owner ist der höchste Benutzer und kann alles tun, einschließlich das Ändern der Datenbankstruktur, das Verwalten von Benutzern und das Zuweisen von Berechtigungen.
- Benutzer:
owner_user
Admin:¶
- Rechte: Kann auf den Tabellen
comments,photosunduserslesen, einfügen, aktualisieren und löschen. Der Admin hat weitreichende Moderationsrechte, aber keine vollständige Kontrolle über die gesamte Datenbank. - Benutzer:
admin_user
Moderator:¶
- Rechte: Der Moderator hat ähnliche Rechte wie der Admin, aber eingeschränkter:
- Auf den Tabellen
commentsundphotoskann der Moderator lesen, einfügen, aktualisieren und löschen. - Auf der Tabelle
userskann der Moderator nur lesen. - Benutzer:
moderator_user
User:¶
- Rechte: Hat eingeschränkten Zugriff:
- Kann auf den Tabellen
photosundcommentslesen, einfügen und aktualisieren, aber keine Daten löschen. - Benutzer:
normal_user
Guest:¶
- Rechte: Kann nur lesen (SELECT) auf den Tabellen
comments,photosundusers. Der Gast hat keinen Zugriff auf Änderungen der Daten. - Benutzer:
guest_user
Hier ist der Code für die Erstellung der verschiedenen Benutzergruppen:
-- Owner
GRANT ALL PRIVILEGES ON friendzone.* TO 'owner_user'@'localhost';
-- Admin
GRANT SELECT, INSERT, UPDATE, DELETE ON friendzone.comments TO 'admin_user'@'localhost';
GRANT SELECT, INSERT, UPDATE, DELETE ON friendzone.photos TO 'admin_user'@'localhost';
GRANT SELECT, UPDATE, DELETE ON friendzone.users TO 'admin_user'@'localhost';
-- Moderator
GRANT SELECT, INSERT, UPDATE, DELETE ON friendzone.comments TO 'moderator_user'@'localhost';
GRANT SELECT, INSERT, UPDATE, DELETE ON friendzone.photos TO 'moderator_user'@'localhost';
GRANT SELECT ON friendzone.users TO 'moderator_user'@'localhost';
-- User
GRANT SELECT, INSERT, UPDATE ON friendzone.photos TO 'normal_user'@'localhost';
GRANT SELECT, INSERT ON friendzone.comments TO 'normal_user'@'localhost';
-- Guest
GRANT SELECT ON friendzone.comments TO 'guest_user'@'localhost';
GRANT SELECT ON friendzone.photos TO 'guest_user'@'localhost';
GRANT SELECT ON friendzone.users TO 'guest_user'@'localhost';
E-Tutorial SQLite¶
01/DO¶
Wir haben ein Video angeschaut und denn Theorieteil gelesen.
Aufpassen
wenn man das Video anklickt lädt es herunter
Was ist das Relationen-Modell?¶
Das Relationen-Modell ist die Grundlage für moderne relationale Datenbanken, wie MySQL, PostgreSQL und Oracle, und bietet eine leistungsstarke und flexible Methode, um strukturierte Daten zu organisieren und zu verwalten. Es erlaubt die Speicherung und Verarbeitung von Daten in Form von Relationen (Tabellen), die durch Operationen wie Selektion, Projektion und Join miteinander verbunden werden können.
Wichtigste Komponenten eines ERML-Modells:¶
- Entitäten: Dinge oder Objekte in der realen Welt, die gespeichert werden, z. B. „Benutzer“, „Fotos“.
- Beziehungen: Wie Entitäten miteinander verbunden sind, z. B. ein „Benutzer“ kann „Kommentare“ zu einem „Foto“ abgeben.
- Attribute: Eigenschaften der Entitäten, z. B. ein „Benutzer“ hat „Name“ und „E-Mail“.
- Schlüssel: Eindeutige Identifikatoren, z. B. eine „Benutzer-ID“.
Beispiel von Beziehungen:¶
- 1:n (Einer-zu-viele): Ein Benutzer kann viele Fotos hochladen.
- m:n (Viele-zu-viele): Ein Benutzer kann viele Kommentare zu vielen Fotos abgeben (diese Beziehung benötigt eine Zwischentabelle).
- 1:1 (Einer-zu-einem): Ein Benutzer hat genau ein Profil.
Das Modell hilft, die Struktur der Datenbank und die Interaktionen der Daten zu visualisieren.
02/TRY¶
-
Wir haben SQLite heruntergeladen
-
dann haben wir eine .db Datei heruntergeladen
Sie werden im Verlaufe dieses Moduls wie folgt vorgehen:
Tutorial 1
- Verstehen, warum der Einsatz einer relationalen Datenbank sinnvoll ist (ab Schritt 4)
- Struktur der relationalen Datenbank aufbauen (ab Schritt 8)
- Daten in die relationale Datenbank einfügen (ab Schritt 15)
Tutorial 2
-
Daten aus der relationalen Datenbank abfragen
-
Repetition
wir haben dann die excel datei geöffnet
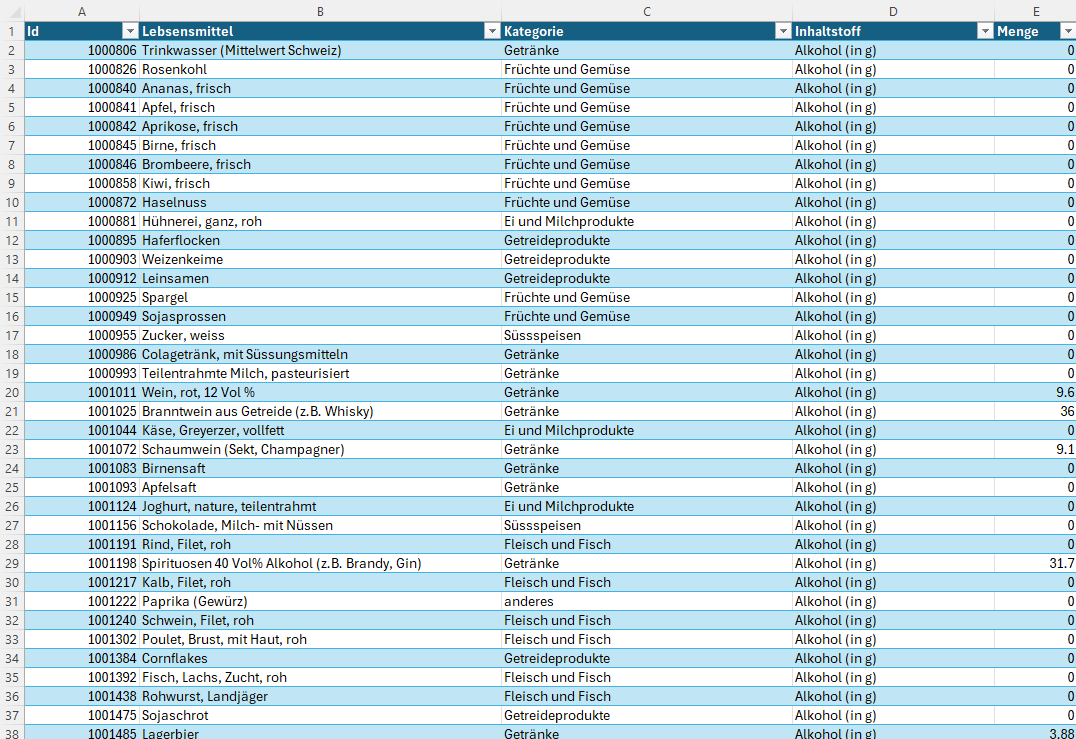
Fragen zum Einstieg¶
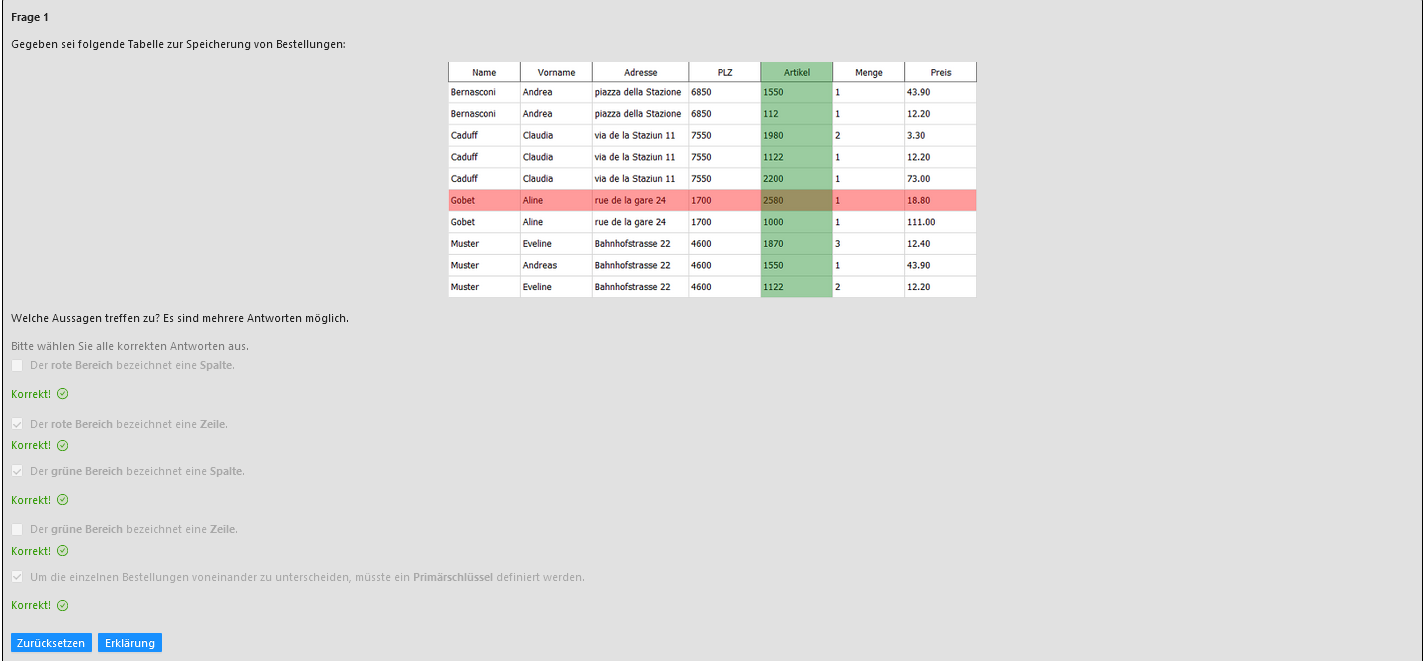
Frage 1:
Sie möchten die Kategorie Getränke in Getraenke umbenennen. Wie würden Sie vorgehen?
Lösung:
Sie müssten in der Spalte Kategorie für alle Lebensmittel, welche sich in der Kategorie Getränke befinden, den Eintrag Getränke ersetzen. Dies wären in Ihrer Datenliste 350 Einträge. Dabei müssen Sie darauf achten, dass Sie keine Änderung vergessen, da sonst inkonsistente Daten entstehen Lebensmittel mit der Kategorie Getraenke und Getränke. Mit der Funktion Suchen und Ersetzen können Sie das relativ einfach erreichen.
Frage 2:
Sie möchten für alle Lebensmittel nur diejenigen Inhaltsstoffe in der Liste behalten, die auch in einem Lebensmittel vorkommen (das heisst eine Menge grösser 0). Wie würden Sie vorgehen?
Lösung:
Sie müssen Zeile für Zeile für alle Lebensmittel prüfen, ob in der Spalte Menge ein Wert grösser 0 eingetragen ist. Falls ja, dann behalten Sie die Zeile in der Datenliste, falls nein, dann können Sie die Zeile löschen. Führen Sie dies durch (z.B. mit einem Filter) besteht Ihre Datenliste "nur" noch aus 776 statt ursprünglich 1175 Zeilen.
Frage 3:
Sie möchten zählen, wie viele verschiedene Lebensmittel es in der Datenliste gibt. Wie würden Sie dies durchführen?
Lösung:
Die Datenliste beinhaltet jedes Lebensmittel mehrmals. Das heisst, Sie
müssen zählen, wie oft ein Lebensmittel vorkommt. Dies können Sie in
Ihrer Tabellenkalkulation mit einem Filter oder der Funktion Daten > Duplikate entfernen erreichen. Es gibt in der Datenliste insgesamt 47 verschiedene Lebensmittel.
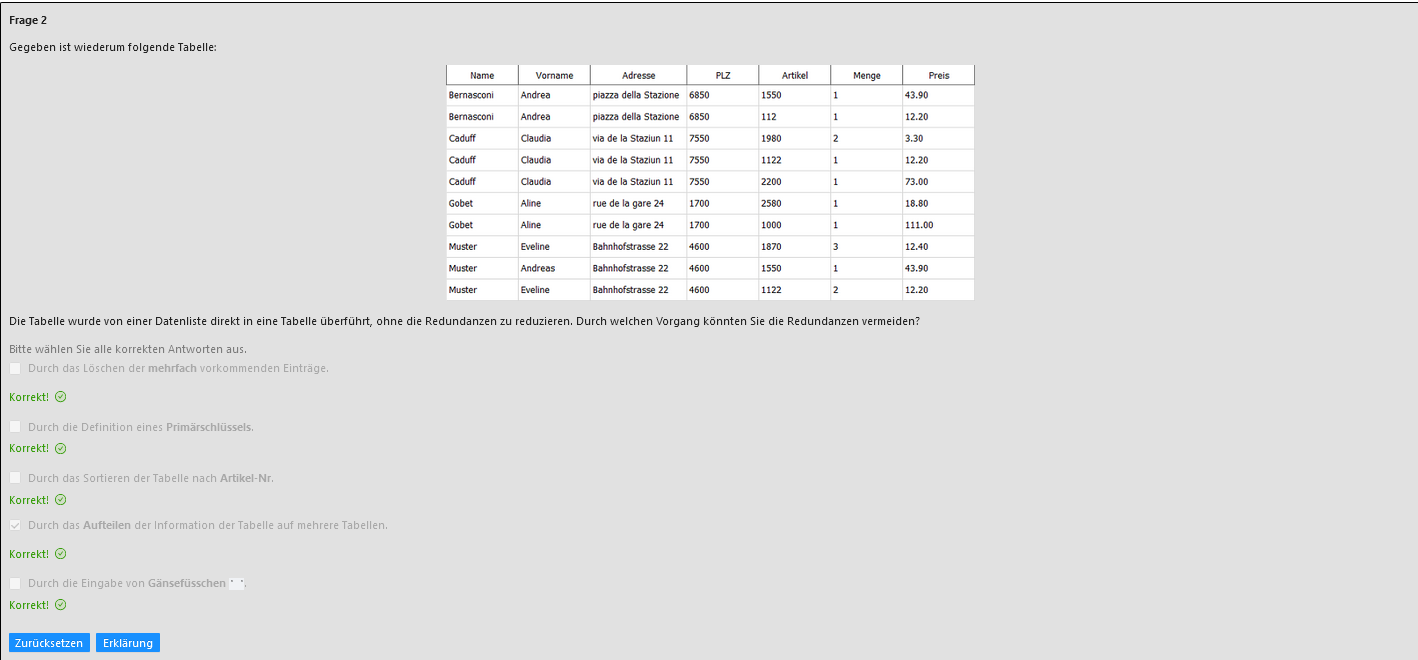
Frage 4:
Was ist der Nachteil, wenn Sie alle Information in einer einzigen Datenliste ablegen?
Lösung:
Eine Datenliste hat typischerweise folgende Nachteile:
- Gleiche Werte kommen wiederholt vor (Redundanz)
- Viele Felder bleiben leer (in der Datenliste der Nährwertdaten wird dies durch den Wert 0.00 ausgedrückt)
- Es können leicht inkonsistente Daten entstehen. Beispiel: Wenn man die Kategorie "Getränke" in "Getraenke" umbenennen möchte und einen Eintrag in der Datenliste vergisst.
Auswahl der Datentypen in SQLite¶
Folgende stehen zur Auswahl:
INTEGERsteht für eine Ganzzahl (Beispiele: 3, 42, -5 oder 0).TEXTsteht für ein Freitext (Beispiele: 'Getränke' oder 'Früchte und Gemüse').REALsteht für eine reelle Zahl (Beispiele: 3.14159, 2.95 oder -100.0).BLOBist eine Abkürzung für Binary Large Object (Beispiel: Abspeichern von Bildern).NUMERICwird verwendet, um reelle Zahlen mit einer vorgegebenen Präzision abspeichern zu können.
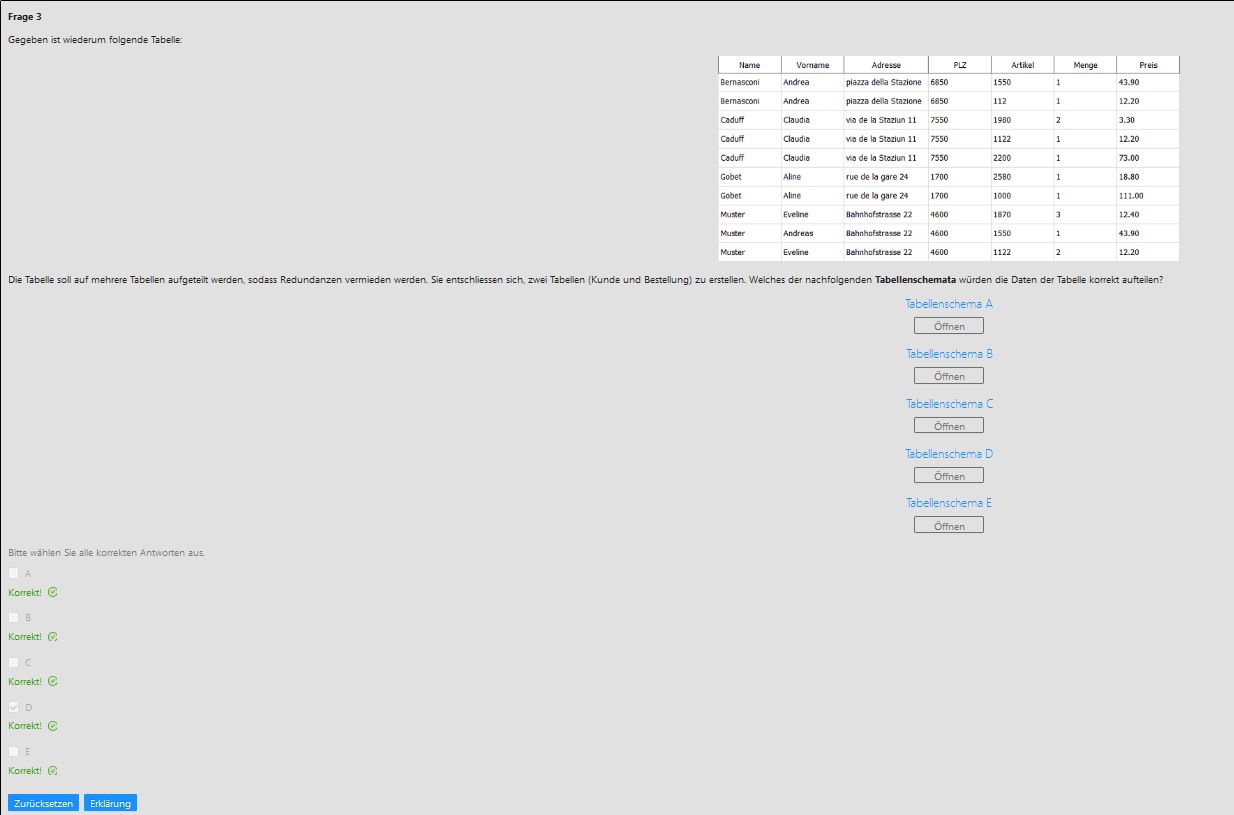
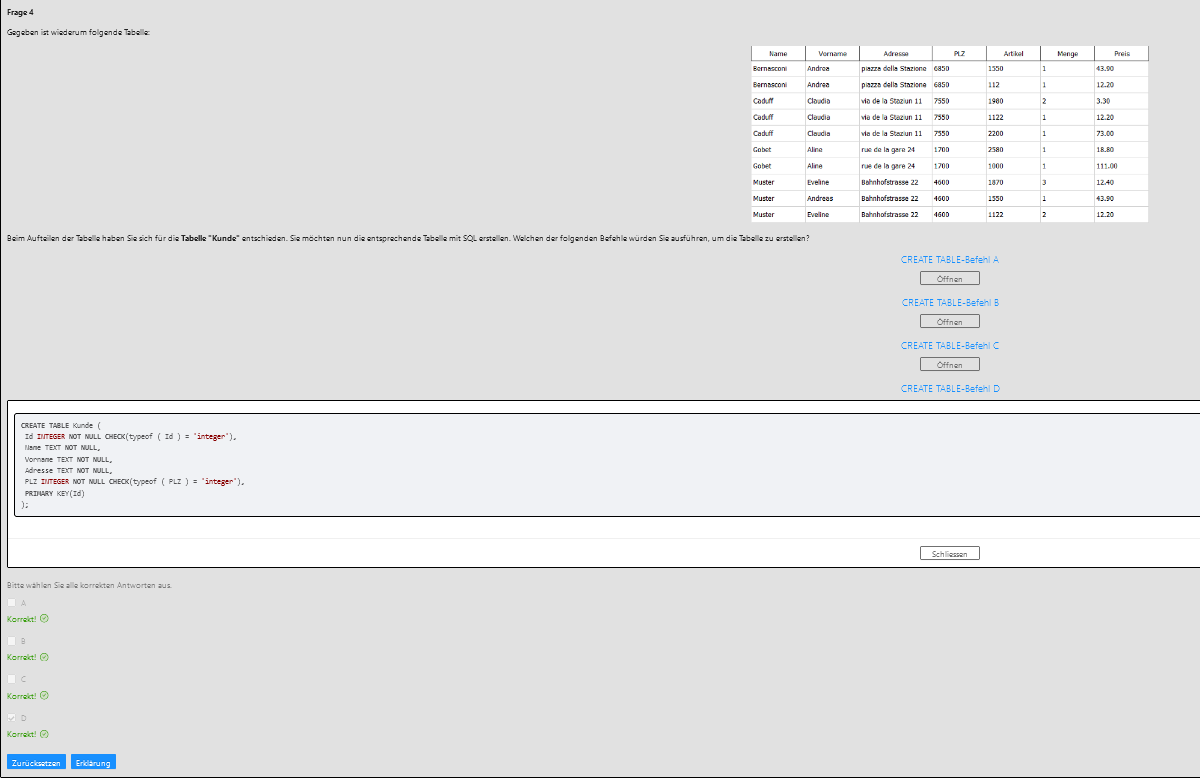
Eine Tabelle in einer relationalen Datenbank hat folgende Eigenschaften:¶
- Jeder Spalte wird ein Name und ein Datentyp zugeordnet.
- Eine Spalte kann als Primärschlüssel einer Tabelle definiert werden. Dies ermöglicht die Identifizierung einer Zeile.
- Leere Einträge können verboten werden, in dem man für eine Spalte Null-Werte nicht erlaubt.
- Mit einer Check-Bedingung können die erlaubten Daten weiter eingeschränkt werden.
Was bedeutet persistent?¶
In SQLite bedeutet "persistent", dass Daten dauerhaft gespeichert werden. Sie bleiben auch nach dem Schließen der Anwendung in einer Datei auf der Festplatte erhalten, bis sie gelöscht oder geändert werden.
Relationale Datenbanken haben ein Regelsystem, welches die explizit definierten Beziehungen zwischen Tabellen ständig kontrolliert. Im Bereich der Datenbanken spricht man von der referentiellen Integrität. Dadurch wird sichergestellt, dass nur gültige Datensätze (das heisst, nur diejenigen, die dem Fremdschlüssel genügen) eingefügt werden dürfen. Die referentielle Integrität hat noch eine zweite Aufgabe, die Sie zu einem späteren Zeitpunkt kennen lernen werden.
Im vorherigen Schritt haben Sie eine mögliche Beziehungsart zwischen zwei Tabellen kennen gelernt. Im Bereich der relationalen Datenbanken spricht man hier von Beziehungstypen. Insgesamt gibt es drei unterschiedliche Beziehungstypen:
- 1:1-Beziehung
- 1:N-Beziehung (dieser Schritt)
- N:M-Beziehung (nächste Schritte)
Bei einer N:M-Beziehung können jedem Datensatz in Tabelle A mehrere Datensätze in Tabelle B zugeordnet sein und umgekehrt
Beziehungen beschreiben, wie Informationen, die über verschiedene Tabellen verteilt sind, gegenseitig logisch verbunden sind. Es gibt verschiedene Beziehungstypen zwischen Tabellen. Die 1:1-Beziehung und 1:N-Beziehung können direkt in der Datenbank dargestellt werden. Zwei Tabellen werden immer über Spalten, die denselben Datentyp aufweisen, verbunden. Dabei wird ein Fremdschlüssel definiert. N:M-Beziehungen können nicht direkt erstellt werden, sondern benötigen eine Zwischentabelle. Die referentielle Integrität kontrolliert die definierten Beziehungen beim Einfügen und Löschen von Daten.
Der Aufbau einer SQL-Abfrage enthält folgende Grundelemente: SELECT...FROM...WHERE...ORDER BY...;
SELECT
Spalten (getrennt durch ein Komma oder Stern) die dargestellt werden
FROM
Tabellen die abgefragt werden
WHERE
Kriterien nach denen gefiltert wird
ORDER BY
Spalten nach denen geordnet wird (getrennt durch ein Komma)
;
Wie wird sichergestellt, dass es zu jeder Zeile aus der Tabelle Lebensmittel maximal nur eine passende Zeile aus der Tabelle Kategorie gibt?
Die Tabellen Lebensmittel und Kategorie stehen in einer 1:N-Beziehung. Diese Beziehung ist in den Tabellen durch die Primärschlüssel-Fremdschlüssel Definition festgehalten. Ein Lebensmittel hat höchstens eine Kategorie, aber eine Kategorie kann mehreren Lebensmitteln zugeordnet werden.
Tabellen können durch eine JOIN-Klausel (Englisch für Verbund) im FROM-Teil verbunden werden. Allgemein lautet die Schreibweise:
A INNER JOIN B ON A.X = B.X
Die Tabelle A wird mit der Tabelle B verbunden. Es werden diejenigen Zeilen berücksichtigt, die gleiche Werte in den Spalten X aufweisen.
Abfrage in SQLite erklärt:
SELECT Lebensmittel.Name, Kategorie.Name, Lebensmittel.Id
FROM Lebensmittel INNER JOIN Kategorie ON Lebensmittel.Kategorie_Id = Kategorie.Id
WHERE Lebensmittel.Id > 1001000 AND (Kategorie.Name = 'Getränke' OR Kategorie.Name = 'Früchte und Gemüse')
ORDER BY Kategorie.Name ASC, Lebensmittel.Name DESC
1. SELECT-Teil¶
sql
Code kopieren
SELECT Lebensmittel.Name, Kategorie.Name, Lebensmittel.Id
- SELECT: Dieser Teil der Abfrage legt fest, welche Spalten aus der Datenbank zurückgegeben werden sollen.
- Lebensmittel.Name: Der Name des Lebensmittels, das aus der Tabelle
Lebensmittelkommt. - Kategorie.Name: Der Name der Kategorie des Lebensmittels, der aus der Tabelle
Kategoriekommt. - Lebensmittel.Id: Die eindeutige ID des Lebensmittels.
2. FROM und INNER JOIN¶
sql
Code kopieren
FROM Lebensmittel INNER JOIN Kategorie ON Lebensmittel.Kategorie_Id = Kategorie.Id
- FROM Lebensmittel: Die Abfrage zieht Daten aus der Tabelle
Lebensmittel. - INNER JOIN Kategorie: Ein INNER JOIN wird durchgeführt, um die Tabelle
Kategoriemit der TabelleLebensmittelzu verbinden. Dies bedeutet, dass nur die Datensätze angezeigt werden, bei denen eine Übereinstimmung zwischen den beiden Tabellen besteht. - ON Lebensmittel.Kategorie_Id = Kategorie.Id: Die Verknüpfung erfolgt über die Spalten
Kategorie_Idaus der TabelleLebensmittelundIdaus der TabelleKategorie. Nur diejenigen Lebensmittel werden zurückgegeben, bei denen dieKategorie_Idmit einer gültigenIdin derKategorie-Tabelle übereinstimmt.
3. WHERE-Bedingung¶
sql
Code kopieren
WHERE Lebensmittel.Id > 1001000 AND (Kategorie.Name = 'Getränke' OR Kategorie.Name = 'Früchte und Gemüse')
- WHERE: Dieser Teil filtert die Ergebnisse basierend auf bestimmten Bedingungen.
- Lebensmittel.Id > 1001000: Nur Lebensmittel mit einer ID, die größer als
1001000ist, werden berücksichtigt. Dies dient dazu, die Auswahl auf Lebensmittel mit höheren IDs zu beschränken. - (Kategorie.Name = 'Getränke' OR Kategorie.Name = 'Früchte und Gemüse'): Diese Bedingung stellt sicher, dass nur Lebensmittel aus den Kategorien "Getränke" oder "Früchte und Gemüse" ausgewählt werden. Es handelt sich um eine ODER-Bedingung, die entweder die Kategorie "Getränke" oder die Kategorie "Früchte und Gemüse" zulässt.
4. ORDER BY¶
sql
Code kopieren
ORDER BY Kategorie.Name ASC, Lebensmittel.Name DESC
- ORDER BY: Dieser Teil bestimmt, wie die Ergebnisse sortiert werden:
- Kategorie.Name ASC: Die Ergebnisse werden zuerst aufsteigend (ASC) nach dem Kategorie-Name sortiert. Das bedeutet, dass die Kategorien alphabetisch von A bis Z geordnet werden.
- Lebensmittel.Name DESC: Innerhalb jeder Kategorie werden die Lebensmittel absteigend (DESC) nach ihrem Namen sortiert. Dies bedeutet, dass die Lebensmittel mit den höchsten alphabetischen Namen zuerst erscheinen.
- SQL-Abfragen können verwendet werden, um tabellenübergreifend nach Daten zu suchen.
- Tabellenübergreifende Abfragen müssen zusätzlich mit
...INNER JOIN...ON...ergänzt werden.
Aufgabe:
Ein Sportler hat in der Vorbereitung für einen Kugelstosswettkampf erfahren, dass Sie bereits mit der Nährwertdatenbank gearbeitet haben und gelangt deshalb mit folgender Frage an Sie: "Um meine Schnellkraft und die Muskelmasse zu erhöhen, suche ich Nahrungsmittel, die viel Protein (>20g) enthalten. Welche Nahrungsmittel können Sie mir empfehlen?"
Bestimmen Sie die Lebensmittel für den Sportler mithilfe einer SQL-Abfrage.
SELECT Lebensmittel.Name, Inhaltsstoff.Name, Lebensmittel_Inhaltsstoff.Menge
FROM Lebensmittel
INNER JOIN Lebensmittel_Inhaltsstoff ON Lebensmittel.Id = Lebensmittel_Inhaltsstoff.Lebensmittel_Id
INNER JOIN Inhaltsstoff ON Lebensmittel_Inhaltsstoff.Inhaltsstoff_Id = Inhaltsstoff.Id
WHERE Lebensmittel_Inhaltsstoff.Menge > 20 AND Inhaltsstoff.Name = 'Protein (in g)'
ORDER BY Lebensmittel_Inhaltsstoff.Menge ASC;
Multiplechoice Fragen:¶