Block 04 | Modul 106¶
Grundlegende Abläufe und Unterschiede¶
Batch Ingestion:
-
Grosse Datenmengen werden gesammelt und in festen Zeitintervallen verarbeitet.
-
Typische Intervallgrössen: stündlich, täglich, wöchentlich.
-
Beispiel: Logdateien, Monatsberichte.
-
Vorteile:
-
Effiziente Verarbeitung grosser Datenmengen.
-
Einfacher umzusetzen.
-
Nachteile:
-
Keine Echtzeitverarbeitung.
-
Verzögerung bis zur Verfügbarkeit der Daten.
Stream Ingestion:
-
Daten werden laufend, nahezu in Echtzeit, verarbeitet.
-
Daten werden einzeln oder in kleinen Paketen sofort übernommen.
-
Beispiel: Sensor-Daten, Finanztransaktionen, Web-Tracking.
-
Vorteile:
-
Nahezu sofortige Verarbeitung.
-
Geeignet für zeitkritische Anwendungen.
-
Nachteile:
-
Komplexer in der Implementierung.
-
Höhere Anforderungen an Stabilität und Skalierbarkeit.
Speicheroptionen neben S3¶¶
-
Amazon EFS (Elastic File System):
Netzlaufwerk, skalierbar für parallelen Zugriff von mehreren Instanzen. -
Amazon EBS (Elastic Block Store):
Blockspeicher für EC2-Instanzen, hoher Datendurchsatz und geringe Latenz.
Weitere Beispiele wären: Glacier (Archivierung), FSx (Windows/Linux File Server), DynamoDB (NoSQL).
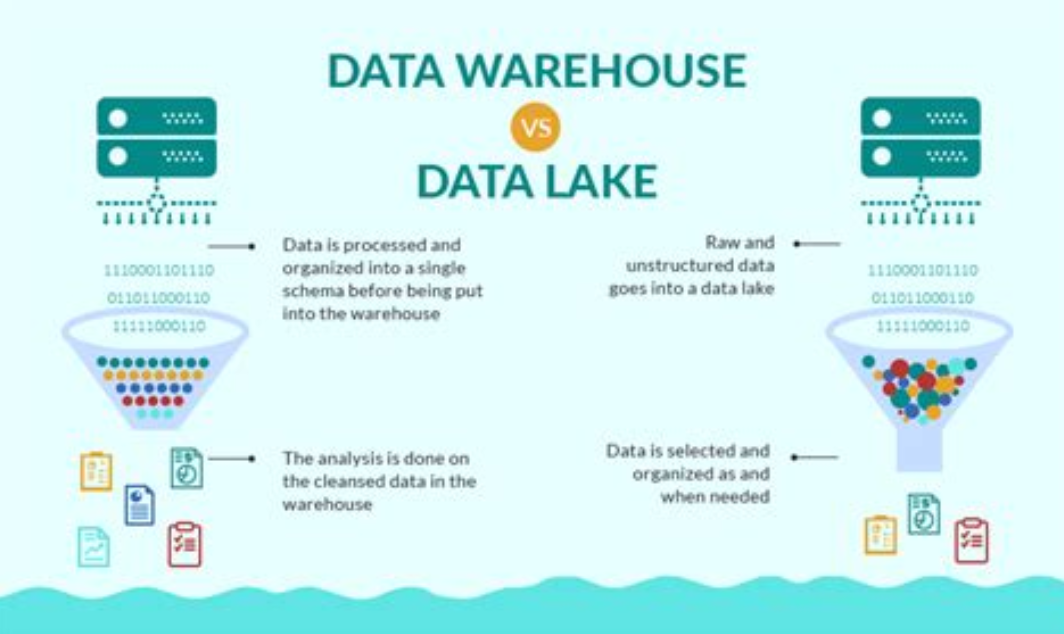
Unterschiede Data Lake vs. Data Warehouse¶¶
Data Lake:
-
Speichert rohe, unstrukturierte und strukturierte Daten.
-
Flexibel für verschiedene Datentypen und Formate.
-
Geringere Speicherkosten.
-
Beispiel: Speicherung von Logdaten, IoT-Daten, Medien.
Data Warehouse:
-
Speichert strukturierte, aufbereitete Daten für Analysen.
-
Optimiert für schnelle Abfragen und Business Intelligence.
-
Höhere Anforderungen an Datenqualität und -struktur.
-
Beispiel: Reporting, Finanzanalysen.
Anwendungsbeispiele¶
-
Data Lake: IoT-Daten von Sensoren, Logdaten von Webservern.
-
Data Warehouse: Umsatzanalysen, Kundenberichte im Controlling.
Kriterien bei der Auswahl einer Datenbank¶
-
Transaktionsanforderungen (z. B. ACID, Caching)
-
Zugriffs- und Aktualisierungshäufigkeit
-
Latenz, Antwortzeiten und Datengrösse
-
Benutzeranforderungen, Failover, Backup und zukünftige Upgrades
Weitere Datenbanktypen¶
- NoSQL (z. B. DynamoDB):
Key-Value, Dokumenten- oder Graphdatenbanken für flexible, schemalose Daten.
Anwendung: Benutzerprofile in Webanwendungen.
Sicherheitskonzept bei Redshift¶
-
Trennung von Service-Sicherheit und DB-Sicherheit:
-
Service-Sicherheit: Netzwerksicherheit, IAM, Verschlüsselung.
-
DB-Sicherheit: Benutzerrechte, Rollen, Zugriff auf Tabellen und Daten.
Definition Big Data¶
-
Big Data bezeichnet grosse, komplexe und schnell wachsende Datenmengen, die mit klassischen Methoden schwer zu verarbeiten sind.
-
Merkmale: Volume, Velocity, Variety, Veracity, Value (5V).
-
Beispiele:
-
Social-Media-Daten (Posts, Bilder, Likes)
-
Sensordaten aus IoT-Geräten (z. B. Smart Homes, Maschinenüberwachung)
Batch vs. Streaming bei Big Data¶
Batch Processing:
-
Verarbeitung grosser Datenmengen in festen Zeitabständen.
-
Geeignet für umfangreiche Analysen und Auswertungen.
-
Vorteile:
-
Effizient bei grossen Datenmengen.
-
Einfacher umzusetzen.
-
Nachteile:
-
Keine Echtzeitverarbeitung.
-
Verzögerte Ergebnisse.
Streaming Processing:
-
Laufende Verarbeitung von Daten nahezu in Echtzeit.
-
Geeignet für zeitkritische Analysen.
-
Vorteile:
-
Schnelle Reaktion auf Ereignisse.
-
Echtzeit-Überwachung möglich.
-
Nachteile:
-
Komplexere Architektur.
-
Höhere Anforderungen an Infrastruktur und Fehlertoleranz.
Herausforderungen bei der Analyse von Big Data¶
-
Datenqualität und -bereinigung
-
Hoher Speicher- und Rechenbedarf
-
Komplexität bei der Datenintegration aus verschiedenen Quellen
-
Datenschutz und Sicherheit
-
Skalierbarkeit der Systeme