Block 01 | Modul 106¶
| Datenanalyse | KI/ML |
|---|---|
| Ist die systematische Analyse grosser Datensätze (Big Data), um Muster und Trends zu finden und umsetzbare Erkenntnisse zu gewinnen | Ist eine Reihe von mathematischen Modellen, die verwendet werden, um Vorhersagen aus Daten in einem Umfang zu treffen, der für Menschen schwierig oder unmöglich ist |
| Verwendet Programmierlogik, um Fragen aus Daten zu beantworten | Verwendet Beispiele aus grossen Datenmengen, um über die Daten zu lernen und Fragen zu beantworten |
| Ist gut für strukturierte Daten mit einer begrenzten Anzahl von Variablen | Ist gut für unstrukturierte Daten und wo die Variablen komplex sind |

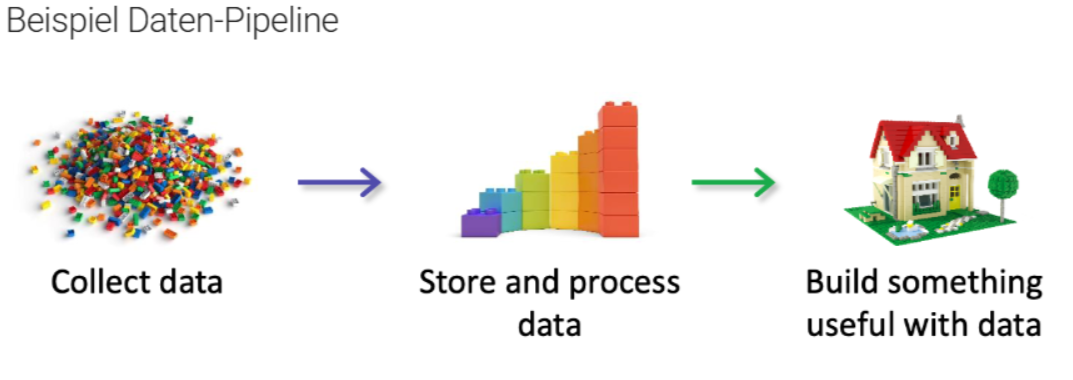
Beispiel Daten Pipeline¶
5Vs¶
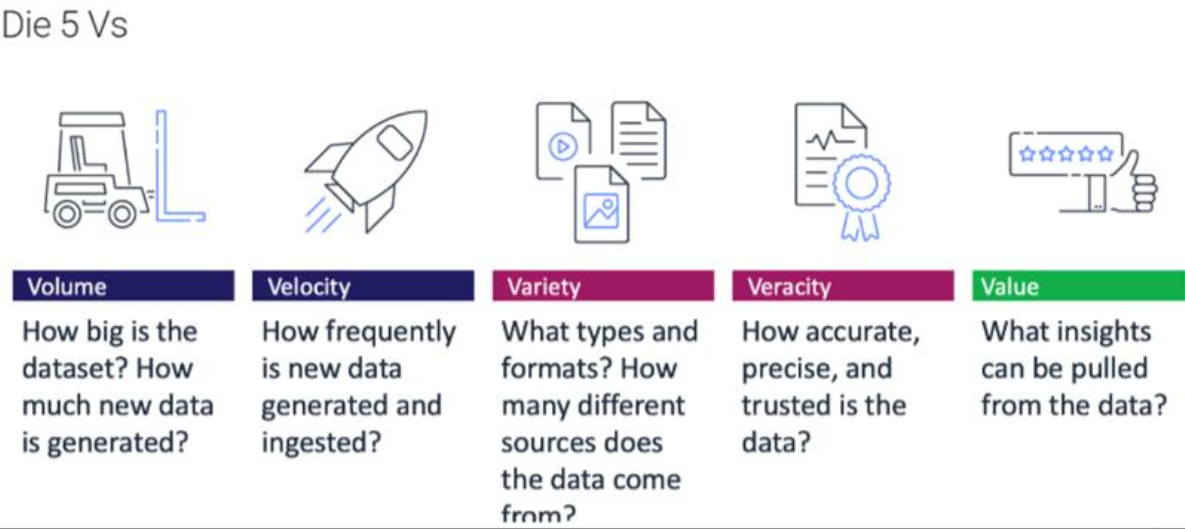
Erklärung 5vs¶
| Konzept | Erklärung | Beispiel |
| ------------------------------ | ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- |
| **Velocity (Geschwindigkeit)** | Beschreibt, wie schnell Daten in eine Pipeline gelangen und sich durch diese bewegen. | Ein Online-Shop verarbeitet Bestellungen schnell, damit sie rasch versendet werden können. |
| **Volume (Datenmenge)** | Bezieht sich auf die enorme Menge an Daten, die täglich generiert wird. | Facebook verarbeitet Milliarden von Posts, Bildern und Videos täglich. |
| **Variety (Vielfalt)** | Daten kommen in verschiedenen Formaten – strukturiert, unstrukturiert und halbstrukturiert. | Netflix analysiert verschiedene Datenformate wie Bewertungen, Videodateien und Nutzungsverhalten. |
| **Veracity (Wahrhaftigkeit)** | Die Qualität und Vertrauenswürdigkeit der Daten ist entscheidend. | Eine Bank überprüft Kundendaten genau, um Betrug zu verhindern. |
| **Value (Wert)** | Daten sind nur dann nützlich, wenn sie einen Mehrwert bieten. | Amazon nutzt Kaufhistorien und Suchverhalten für gezielte Produktempfehlungen. |
Rolle_Data_Engineer¶
Ein Data Engineer entwickelt die Infrastruktur, die grosse Datenmengen speichert, verarbeitet und bereitstellt. Er baut Daten-Pipelines, die Daten aus verschiedenen Quellen sammeln, bereinigen und schnell zugänglich machen.
**Beispiel:**
Ein Online-Shop verarbeitet täglich Kundendaten. Der Data Engineer sorgt dafür, dass diese effizient gespeichert und analysiert werden, sodass gezielte Produktempfehlungen möglich sind.





Modul 3:¶







Data Typen¶
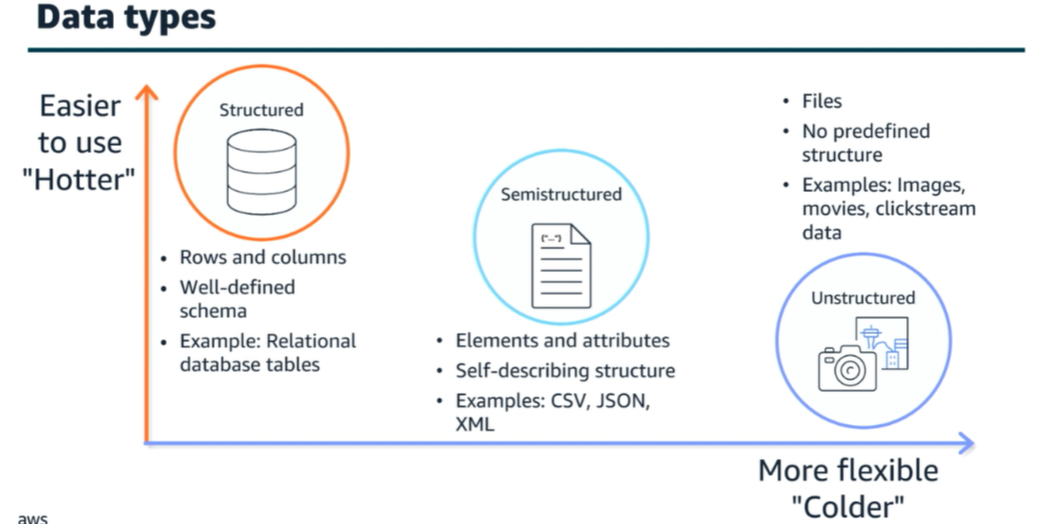




| AWS-Service | Einfache Erklärung |
|---|---|
| Amazon S3 | Speichert Dateien und Daten in der Cloud |
| Amazon Redshift | Macht große Daten für Berichte und Abfragen schnell nutzbar |
| AWS Glue | Bereitet Daten automatisch auf (z. B. sortieren, bereinigen) |
| Amazon Athena | Führt SQL-Abfragen direkt auf Daten in S3 aus |
| Amazon Kinesis | Verarbeitet Daten in Echtzeit (z. B. Live-Datenströme) |
| Amazon DynamoDB | Schnelle Datenbank für einfache, schnelle Abfragen |
| Amazon RDS | Verwalten von normalen Datenbanken wie MySQL oder PostgreSQL |
| Amazon Aurora | Starke, schnelle Datenbank mit hoher Sicherheit |
| Amazon QuickSight | Erstellt schöne Diagramme und Dashboards |
| Amazon SageMaker | Hilft beim Erstellen von KI- und Machine-Learning-Modellen |
| Amazon Bedrock | Macht KI-Modelle über einfache APIs nutzbar |
| Amazon Q Developer | KI-Hilfe für Entwickler beim Schreiben von Code |
| AWS Lambda | Führt Code automatisch aus, wenn etwas passiert |
| AWS CloudFormation | Baut AWS-Infrastruktur automatisch mit Code |
| AWS DataSync | Überträgt Daten von deinem PC/Server zu AWS |
| AWS Step Functions | Verbindet mehrere Schritte zu einem automatischen Ablauf |
| Amazon CloudWatch | Überwacht, ob alles in der Cloud richtig funktioniert |
| AWS IAM | Bestimmt, wer was in der Cloud darf |
| AWS CloudTrail | Zeichnet auf, wer was in AWS gemacht hat |