Block 02 | Modul 106¶
AWS Well-Architected Framework and Lenses¶
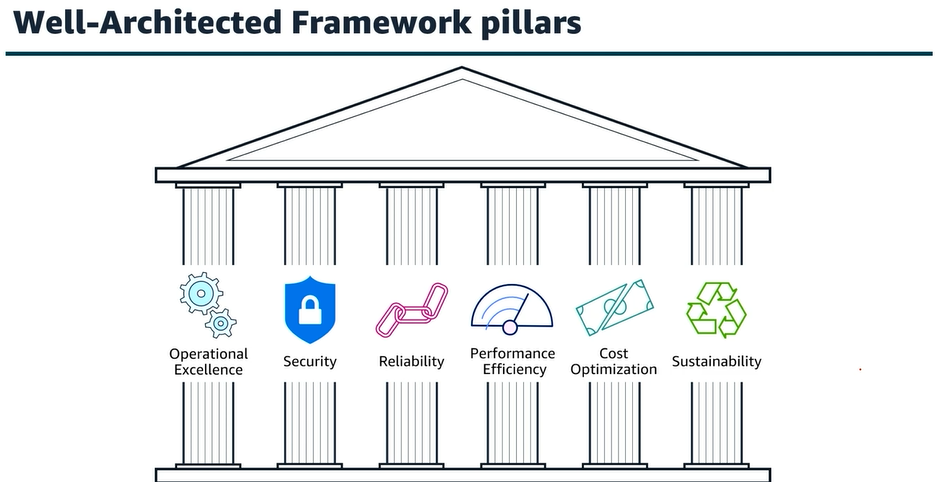
- Das Well-Architected Framework bietet Best Practices und Designleitfäden auf sechs Säulen
- Die Well-Architected Framework-Objektive erweitern die Leitlinien, sodass sie sich auf bestimmte Bereiche konzentrieren
- Die Data Analytics Lens bietet Orientierungshilfen, die bei Entwurfsentscheidungen in Bezug auf die einzelnen Datenelemente (Volumen, Geschwindigkeit, Vielfalt, Richtigkeit und Wert) helfen.
| Säule | Beschreibung |
|---|---|
| Operational Excellence | Fokus auf Betrieb, Überwachung und kontinuierliche Verbesserung der Systeme. |
| Security | Schutz von Daten, Systemen und Workloads durch Sicherheitsmechanismen. |
| Reliability | Fähigkeit eines Systems, Ausfälle zu vermeiden und sich davon zu erholen. |
| Performance Efficiency | Effiziente Nutzung von Ressourcen für eine optimale Leistung. |
| Cost Optimization | Wirtschaftliche Nutzung von Ressourcen und Kostenkontrolle. |
| Sustainability | Umweltbewusste Nutzung von IT-Ressourcen zur Minimierung des Energieverbrauchs. |
Moderne Datenarchitekturen mit AWS – Überblick und Konzepte¶
1. Das AWS Well-Architected Framework¶
Das AWS Well-Architected Framework ist ein Leitfaden für den Aufbau sicherer, leistungsfähiger, widerstandsfähiger und effizienter Infrastrukturen in der Cloud. Es basiert auf sechs Säulen:
-
Betriebseffizienz
-
Sicherheit
-
Zuverlässigkeit
-
Leistungsoptimierung
-
Kostenoptimierung
-
Nachhaltigkeit
Sogenannte Lenses (z. B. die Data Analytics Lens) spezialisieren diese Prinzipien auf bestimmte Anwendungsbereiche. Die Data Analytics Lens unterstützt beim Design analytischer Systeme, insbesondere im Hinblick auf:
-
Datenvolumen
-
Geschwindigkeit (wie schnell Daten ankommen und verarbeitet werden müssen)
-
Vielfalt (unterschiedliche Formate und Quellen)
-
Richtigkeit (Qualität und Vertrauenswürdigkeit)
-
Wert (geschäftlicher Nutzen der Daten)
2. Die Evolution von Datenarchitekturen¶
Datenarchitekturen haben sich in den letzten Jahren grundlegend verändert. Gründe dafür sind:
-
Wachsende Mengen an Daten (Big Data)
-
Unterschiedliche Formate (strukturierte, semi-strukturierte, unstrukturierte Daten)
-
Der Wunsch nach Echtzeitanalyse und hoher Flexibilität
Moderne Architekturen kombinieren daher verschiedene Speicherformen (z. B. Data Lake und Data Warehouse) und versuchen, alle Datenquellen in eine einheitliche Informationsbasis zu integrieren – Stichwort: „Single Source of Truth“.
3. Moderne Datenarchitektur mit AWS – Pipeline von Ingestion bis Nutzung¶
Datenaufnahme und Speicherung (Ingestion & Storage)¶
-
AWS nutzt spezialisierte Tools, um Daten je nach Typ aufzunehmen.
-
Amazon S3 dient als Data Lake, in dem Rohdaten gespeichert werden. Die Daten werden dort nach Zustand organisiert (z. B. „Rohdaten“, „bereinigt“, „bereit zur Analyse“).
-
Amazon Redshift ist das Data Warehouse, das strukturierte Daten performant analysieren kann.
-
AWS Glue und Lake Formation stellen den Datenkatalog bereit, in dem alle Metadaten (Beschreibung der Daten, Herkunft etc.) gespeichert sind.
-
Mit Amazon Redshift Spectrum können Daten direkt im S3-Data Lake abgefragt werden, ohne sie zuerst verschieben zu müssen.
Verarbeitung und Nutzung (Processing & Consumption)¶
-
Die Verarbeitungsschicht transformiert Daten in einen nutzbaren Zustand. Unterstützt werden:
-
SQL-basiertes ELT
-
Big-Data-Workloads
-
Nahezu-Echtzeit-ETL
-
In der Nutzungsschicht werden Daten analysiert, z. B. durch:
-
SQL-Abfragen
-
BI-Dashboards (z. B. mit Amazon QuickSight)
-
Machine Learning
Die Architektur stellt eine zentrale Schnittstelle bereit, über die alle Datenquellen zugänglich sind – unabhängig von Format oder Herkunft.
4. Streaming Analytics Pipeline¶
Streaming Analytics ist besonders wichtig, wenn Daten in Echtzeit verarbeitet werden müssen (z. B. Sensoren, Logdaten, Finanztransaktionen).
-
Ein Stream (z. B. über Amazon Kinesis) nimmt laufend Daten von Produzenten (wie Anwendungen oder Geräten) auf.
-
Diese Daten können zwischengespeichert, direkt verarbeitet und an Konsumenten weitergeleitet oder in Speicherlösungen (S3, Redshift etc.) überführt werden.
Typische Anwendungen:
-
Betrugserkennung in Echtzeit
-
Live-Dashboards
-
Alarme und automatisierte Reaktionen
Activity E-Bike¶
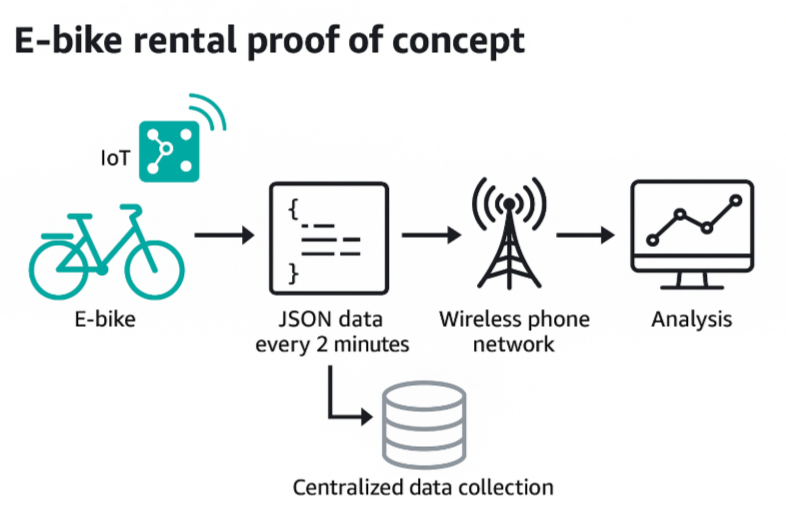
E-Bike Rental Proof of Concept¶

Szenario zusammengefasst
- 50 E-Bikes mit IoT-Geräten
- JSON-Daten alle 2 Minuten
- Übertragung via Mobilfunknetz
- Zentrale Datenspeicherung
- Ziel: Analyse und Auswertung
IoT (Internet of Things)
| Komponente | Funktion |
|---|---|
| GPS-Modul | Erfasst Standort und Geschwindigkeit |
| Gyrosensor / Beschleunigungssensor | Erkennt Bewegung, Fahrverhalten oder Stürze |
| Akku-Monitoring | Misst Ladezustand und Energieverbrauch |
| Mobilfunkchip | Sendet Daten (z. B. alle 2 Minuten) über Mobilnetz |
| Mikrocontroller | Steuert alles und verpackt Daten als JSON |
Erklärung
| Schritt | Beschreibung |
|---|---|
| 1. E-Bike mit IoT-Gerät | Jedes E-Bike ist mit einem IoT-Sensor ausgestattet. Dieser misst kontinuierlich wichtige Daten wie GPS-Position, Akkustand, Fahrzeit, Geschwindigkeit etc. Der Sensor ist über den E-Bike-Akku mit Strom versorgt. |
| 2. JSON-Daten alle 2 Minuten | Die gemessenen Daten werden in einem JSON-Format verpackt. Dieses Format ist leichtgewichtig, lesbar und maschinenfreundlich – ideal für die Übertragung und spätere Verarbeitung. Alle 2 Minuten wird ein JSON-Datensatz gesendet. |
| 3. Übertragung über Mobilfunknetz | Die JSON-Daten werden über das drahtlose Mobilfunknetz verschickt – ähnlich wie eine SMS oder mobile Internetverbindung. Das ermöglicht ständige Konnektivität, auch wenn das Bike unterwegs ist. |
| 4. Zentrale Datensammlung (Cloud/Server) | Alle eintreffenden JSON-Daten werden an eine zentrale Stelle gesendet – meist in die Cloud (z. B. AWS S3 oder eine relationale Datenbank). Hier können sie gespeichert, verwaltet und archiviert werden. |
| 5. Analyse | Die gesammelten Daten werden mit Analyse-Tools (z. B. BI-Dashboards wie QuickSight, Power BI oder Python-Skripten) ausgewertet. Ziel: Nutzungsmuster erkennen, Auslastung optimieren, Ladezyklen planen oder neue Standorte finden. |
Zusammenfassung Modul 4¶
1. Vergleich: ETL vs. ELT¶
| Merkmal | ETL (Extract → Transform → Load) | ELT (Extract → Load → Transform) |
|---|---|---|
| Reihenfolge | Transformation vor dem Laden | Transformation nach dem Laden |
| Vorteil | Schnellere Abfragen, saubere Zielstruktur | Flexibler, besser für große Datenmengen |
| Nachteil | Weniger flexibel bei Änderungen | Höherer Speicherbedarf, komplexe Verwaltung |
| Einsatzbereich | Strukturierte Daten (z. B. Berichte) | Unstrukturierte Daten (z. B. Data Lakes) |
Data-Driven-Decisions¶
Datengesteuerte Entscheidungen bedeuten, dass Unternehmen systematisch Daten nutzen, um fundierte Entscheidungen zu treffen. Dank der zunehmenden Menge und Vielfalt an Daten sowie günstigerer Rechenleistung setzen immer mehr Unternehmen auf Datenanalyse und künstliche Intelligenz (KI), insbesondere maschinelles Lernen (ML).
- Datenanalyse nutzt statistische Methoden und Programmierlogik, um Erkenntnisse zu gewinnen.
- KI/ML lernt aus Beispielen und kann komplexe Muster in grossen, auch unstrukturierten Datensätzen erkennen.
Beispiele: Empfehlungssysteme, Betrugserkennung, personalisierte Werbung oder landwirtschaftliche Entscheidungen via IoT.
Vier Arten von Analyse:
- Beschreibend (Was ist passiert?),
- Diagnostisch (Warum ist es passiert?),
- Prädiktiv (Was wird passieren?),
- Präskriptiv (Was sollen wir tun?).
Herausforderungen: Daten verlieren mit der Zeit an Wert, Sicherheit und Speicherkapazität müssen bedacht werden. Der Nutzen hängt davon ab, wie schnell und sinnvoll Daten verarbeitet werden können.
Fazit: Mehr Daten + bessere Technologie = bessere Entscheidungen – aber nur, wenn sie richtig genutzt werden.
The data pipeline - infrastructure for data-driven decisions¶
Einleitung¶
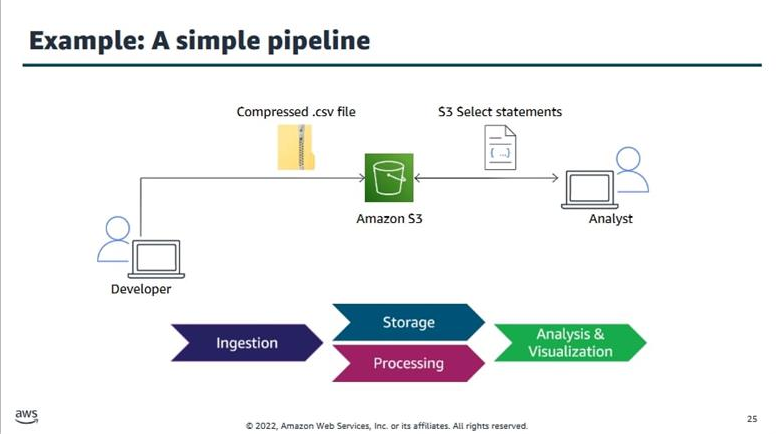
Eine Data Pipeline bezeichnet eine strukturierte Abfolge von Prozessen zur Erfassung, Verarbeitung, Speicherung und Analyse von Daten. Sie dient dazu, Daten aus verschiedenen Quellen automatisiert und zuverlässig zu transportieren und für datenbasierte Entscheidungen bereitzustellen. Solche Pipelines sind ein zentraler Bestandteil moderner Cloud- und Big-Data-Architekturen.
Bestandteile einer Data Pipeline¶
-
Datenquelle (Source Layer) Datenquellen sind Systeme oder Geräte, aus denen Rohdaten stammen. Beispiele hierfür sind relationale Datenbanken, APIs, Sensoren (IoT), Logs von Webanwendungen oder Drittanbieter-Dienste.
-
Datenaufnahme (Ingestion Layer) Dieser Schritt bezieht sich auf die Aufnahme und Übertragung der Rohdaten in das Verarbeitungssystem. Je nach Anforderungen kann dies in Echtzeit (Streaming) oder in festgelegten Zeitintervallen (Batch) geschehen. Gängige Werkzeuge: AWS Kinesis, Apache Kafka, AWS DataSync.
-
Datenverarbeitung (Processing Layer) In diesem Schritt werden die aufgenommenen Rohdaten transformiert, bereinigt, validiert oder angereichert. Die Transformation kann z. B. die Umwandlung von Datenformaten, Aggregationen oder das Zusammenführen mehrerer Datenquellen umfassen. Typische Tools sind AWS Glue, Apache Spark, AWS Lambda.
-
Datenspeicherung (Storage Layer) Nach der Verarbeitung werden die strukturierten Daten dauerhaft gespeichert. Je nach Anwendungsfall können dafür Data Warehouses, relationale Datenbanken oder Data Lakes verwendet werden. Beispiele: Amazon Redshift, Amazon S3, Amazon RDS.
-
Datenanalyse und Visualisierung (Analytics Layer)
In der letzten Schicht werden die gespeicherten Daten durch Analyse- und Visualisierungswerkzeuge für geschäftliche Entscheidungen nutzbar gemacht. Dies kann interaktiv oder automatisiert erfolgen. Werkzeuge in diesem Bereich sind z. B. Amazon QuickSight, Tableau oder Jupyter Notebooks.
Beispiel einer Simple Pipeline¶
The role of the data engineer in data-driven organizations¶
Wichtige Erkenntnisse¶
-
Das Data Engineering konzentriert sich in erster Linie auf die Infrastruktur, die die Daten durchlaufen, während der Data Scientist mit den Daten in der Pipeline arbeitet.
-
Um die richtige Pipeline zu erstellen, müssen Sie Fragen zu den gewünschten Ergebnissen und den Daten stellen und dann Ihre Antworten iterieren, wenn Sie mehr erfahren.
-
Data Engineering konzentriert sich in erster Linie auf die Infrastruktur, die die Daten durchlaufen, während der Data Scientist mit den Daten in der Pipeline arbeitet.
Modernize
- wechseln Sie von lokalen zu Cloud-basierten Diensten
- migrieren Sie zu speziell entwickelten Tools und Datenspeichern
- bauen Sie lose gekoppelte Pipelines auf.
Unify
- Aufbrechen von Datensilos
- Demokratisierung des Zugriffs
- Ausstattung der Benutzer mit Tools zur Visualisierung ihrer eigenen Erkenntnisse
- Nutzung eines Data Lake und Ausführung von Abfragen direkt auf den Daten
- Unterstützung einer vereinfachten Governance und des Austauschs zwischen dem Data Lake und zweckgebundenen Speichern.
Innovate
- gehen Sie von der reaktiven zur proaktiven Entscheidungsfindung über
- integrieren Sie KI/ML in die Entscheidungsfindung und erschließen Sie neue Erkenntnisse aus riesigen Mengen unstrukturierter Daten
- nutzen Sie die Vorteile von Cloud-Diensten mit KI/ML-Funktionen, die die Nutzung von ML demokratisieren.
Programme von AWS¶
| Dienst / Begriff | Aufgabe (kurz & einfach) | Beispiel |
|---|---|---|
| S3 | Speicher für Dateien und Daten (z. B. Backups, Bilder, Logs). | |
| Athena | SQL-Abfragen direkt auf Daten in S3 ausführen. | |
| Glue | Daten vorbereiten, transformieren und katalogisieren (ETL-Tool). | |
| Crawler (in Glue) | Erkennt automatisch Struktur von Daten und erstellt einen Datenkatalog. | |
| View (in Athena/Redshift) | Virtuelle Tabelle: zeigt gefilterte oder kombinierte Daten aus anderen Tabellen. | |
| Redshift | Data Warehouse für schnelle Analyse grosser Datenmengen. | |
| EMR | Big-Data-Verarbeitung mit Hadoop/Spark (z. B. für Machine Learning). | |
| Step Functions | Abläufe (Workflows) automatisieren und koordinieren. | |
| AWS Cloud9 | Webbasierte IDE zum Programmieren direkt in der Cloud. | |
| IAM | Zugriffskontrolle: Wer darf was in AWS tun? | |
| SQL | Sprache zur Abfrage und Bearbeitung von Datenbanken. | |
| DDL | Teil von SQL: erstellt und verändert Tabellen (z. B. CREATE TABLE). | |
| DML | Teil von SQL: ändert Daten (z. B. INSERT, UPDATE, DELETE). | |
| Amazon RDS | Managed Relational Database Service für strukturierte Daten | |
| DynamoDB | NoSQL-Datenbank | |
| Data Splitting | Aufteilung der verfügbaren Daten in Training, Validation und Test. Ziel: Überprüfung und Verbesserung der Modellqualität, Vermeidung von Overfitting. |
1000 Bilder → 700 Training, 150 Validation (für Hyperparameter-Tuning), 150 Test (für finale Bewertung) |
| SMOTE | erstellt künstliche Beispiele der seltenen Klasse. | Bei Kreditkartenbetrug erzeugt SMOTE mehr Betrugsfälle zum Lernen. |
| Imputation | Fehlende Werte ersetzen, z. B. durch Mittelwert. | |
| Data Insights Balken, Linien, GIS | sind erkenntnisreiche Muster und Trends aus Datenanalysen, die Geschäftsentscheidungen verbessern und Wettbewerbsvorteile schaffen. |
Netflix erkennt: Nutzer schauen freitags mehr Thriller → gezieltes Content-Marketing am Freitag |
| Aufgabe | Dienst (AWS) | Erklärung (kurz) |
|---|---|---|
| Big Data Verarbeitung | Amazon EMR | Bearbeitet grosse Datenmengen (z. B. Logs). |
| Log-Analyse | OpenSearch Service | Durchsucht und analysiert Logs. |
| Data Warehousing | Amazon Redshift | Schnelle Analysen grosser Datenmengen. |
| Machine Learning | SageMaker | Baut & trainiert KI-Modelle. |
| Nonrelat. Datenbanken | DynamoDB | Speichert flexible, schnelle Daten (NoSQL). |
| Relat. Datenbanken | Aurora | Klassische SQL-Datenbank in der Cloud. |
| unterschiedliche Quellen vereinheitlichen | Athena | Daten aus verschiedenen Quellen (z. B. S3, relationalen Datenbanken) mit SQL vereinheitlichen. |