DO-Part E-Tutorial¶
Note
08.01.2025 8:15 Version 1
| Begriff | Erklärung |
|---|---|
| Datenliste | Eine Sammlung von Daten, die in Listenform organisiert sind, aber keine feste Struktur wie in Datenbanken haben. |
| Datenbank | Eine organisierte Sammlung von Daten, die elektronisch gespeichert und verwaltet werden, oft in Tabellenform. |
| Tabellen | Strukturierte Daten in Zeilen und Spalten, die in einer relationalen Datenbank gespeichert werden. |
| Attribute | Spalten in einer Tabelle, die bestimmte Eigenschaften oder Merkmale eines Datensatzes beschreiben. |
| Beziehungstypen | Verbindungen zwischen Tabellen in einer Datenbank, z. B. 1:1, 1:N oder N:M Beziehungen. |
| Primärschlüssel | Ein Attribut oder eine Kombination von Attributen, das jeden Datensatz in einer Tabelle eindeutig identifiziert. |
| Fremdschlüssel | Ein Attribut in einer Tabelle, das auf den Primärschlüssel einer anderen Tabelle verweist, um Beziehungen zu erstellen. |
| Metadaten | Daten über Daten, wie z. B. Informationen über die Struktur, Bedeutung und Nutzung der Daten in der Datenbank. |
| Referentielle Integrität | Eine Regel, die sicherstellt, dass Fremdschlüssel in einer Tabelle nur auf existierende Primärschlüssel in einer anderen Tabelle verweisen. |
| Redundanz | Die mehrfache Speicherung derselben Daten, was Platzverschwendung und Inkonsistenzen verursachen kann. |
| Relationale Operatoren | Operationen wie Selektion, Projektion und Join, die in relationalen Datenbanken verwendet werden, um Daten zu manipulieren. |
| Logische Operatoren | Operatoren wie AND, OR und NOT, die in SQL und anderen Sprachen verwendet werden, um Bedingungen zu verknüpfen. |
| SQL | Structured Query Language, eine Sprache zur Verwaltung und Abfrage von Daten in relationalen Datenbanken. |
2 Vorbereitendes¶
2.1 Einlesen der bereitgestellten Datenbank¶
- Womit müssen Sie den Code ergänzen, damit Sie eine SQL-Abfrage machen können?
SELECT * FROM Ankunftszeiten;
SELECT * FROM Haltepunkt;
SELECT * FROM Haltestelle;
SELECT * FROM Linie;
3 Aufgaben¶
3.1 Metadaten der relationalen Datenbank analysieren¶
Table Ankunftszeiten
CREATE TABLE "Ankunftszeiten" (
"Id" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Haltepunkt_Id" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Linie_Id" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Datum" TEXT NOT NULL,
"Delay" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
PRIMARY KEY("Id"),
FOREIGN KEY("Haltepunkt_Id") REFERENCES "Haltepunkt"("Id"),
FOREIGN KEY("Linie_Id") REFERENCES "Linie"("Id")
);
Table Haltepunkt
CREATE TABLE "Haltepunkt" (
"Id" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Haltestelle_Id" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Latitude" REAL,
"Longitude" REAL,
PRIMARY KEY("Id"),
FOREIGN KEY("Haltestelle_Id") REFERENCES "Haltestelle"("Id")
);
Table Haltestellen
CREATE TABLE "Haltestelle" (
"Id" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Kurzname" TEXT NOT NULL,
"Langname" TEXT NOT NULL,
PRIMARY KEY("Id")
);
Table Linie
CREATE TABLE "Linie" (
"Id" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Nummer" INTEGER NOT NULL CHECK(typeof("Id") = 'integer'),
"Fahrwegbezeichnung" TEXT NOT NULL,
PRIMARY KEY("Id"),
UNIQUE("Nummer","Fahrwegbezeichnung")
);
Betrachten Sie die Datenbank-Tabellenübersicht unter Tabelle 1 und beantworten Sie folgende Fragen:
-
Welche Attribute eignen sich als Primärschlüssl? Markieren Sie diese mit “PK”.
-
Wie viele Fremdschlüssel gibt es insgesamt in der Datenbank? Wozu dienen sie? Markieren Sie diese mit “FK”.
-
Zeichnen Sie die Beziehungstypen zwischen den Tabellen ein und beschrifte Sie diese.
-
In der Datenbank gibt es eine Zwischentabelle. Wie heisst sie und wozu dient sie
Antworten der Fragen:
Antwort auf die Fragen:¶
- Primärschlüssel (PK):
- Ankunftszeiten: "Id" ist der Primärschlüssel (PK).
- Haltepunkt: "Id" ist der Primärschlüssel (PK).
- Haltestelle: "Id" ist der Primärschlüssel (PK).
- Linie: "Id" ist der Primärschlüssel (PK).
- Fremdschlüssel (FK):
- Es gibt 3 Fremdschlüssel:
- Ankunftszeiten: "Haltepunkt_Id" ist ein FK, der auf "Haltepunkt(Id)" verweist.
- Ankunftszeiten: "Linie_Id" ist ein FK, der auf "Linie(Id)" verweist.
- Haltepunkt: "Haltestelle_Id" ist ein FK, der auf "Haltestelle(Id)" verweist.
- Beziehungstypen:
- Ankunftszeiten ↔ Haltepunkt: 1:N (Ein Haltepunkt kann mehrere Ankunftszeiten haben).
- Ankunftszeiten ↔ Linie: 1:N (Eine Linie kann mehrere Ankunftszeiten haben).
- Haltepunkt ↔ Haltestelle: 1:N (Eine Haltestelle kann mehrere Haltepunkte haben).
- Zwischentabelle:
- In diesem Fall gibt es keine explizite Zwischentabelle, aber die Ankunftszeiten-Tabelle könnte als eine Art Zwischentabelle dienen, da sie Beziehungen zwischen Haltepunkt und Linie aufnimmt
Antwort auf die Fragen 3.2¶
3.2.1¶
Anzahl Haltestellen
Es gibt 715 Haltestellen
3.2.1: Anzahl Haltestellen
(Anzahl Haltestellen)
(1) 715
3.2.2¶
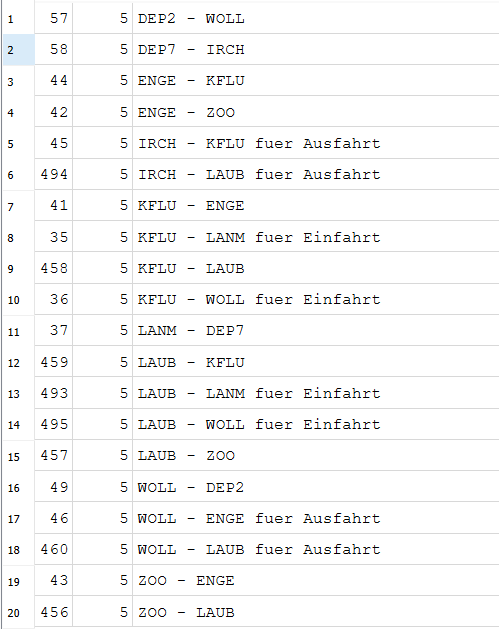
Linien von Enge zum Zoo
Auf der GUI sind wir zu Browse Data und dort haben wir die Linien-Tabelle ausgewählt und einen Filter geschrieben.

Linie 5 und Linie 6 fahren von ENGE - ZOO
3.2.3¶
Fahrwege der Linie 5
mann muss beim Filter =5 eingeben sodass nur nummer 5 angezeigt wird sonst werden auch ander zum beispiel 35 angezeigt
3.2.4¶
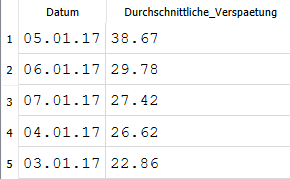
Tag mit der grössten Verspätung
code zum überprüfen:
SELECT Datum, ROUND(AVG(Delay), 2) AS Durchschnittliche_Verspaetung
FROM Ankunftszeiten
GROUP BY Datum
ORDER BY Durchschnittliche_Verspaetung DESC;
Code erklärt:
**SELECT Datum, ROUND(AVG(Delay), 2) AS Durchschnittliche_Verspaetung**: Wählt das Datum und den durchschnittlichen Delay (Verspätung) aus. Der Durchschnitt wird auf 2 Dezimalstellen gerundet.**FROM Ankunftszeiten**: Die Daten kommen aus der Tabelle "Ankunftszeiten".**GROUP BY Datum**: Gruppiert die Ergebnisse nach Datum, sodass der Durchschnitt für jedes Datum berechnet wird.**ORDER BY Durchschnittliche_Verspaetung DESC**: Sortiert die Daten nach dem Durchschnitt der Verspätung in absteigender Reihenfolge (höchster Durchschnitt zuerst).
3.3 Datenanalyse über mehrere Tabellen¶
3.3.1¶
Linie mit der grössten Verspätung
Die linien_ID habe ich bei der Tabelle Linie eingegeben(719)

DIe Tabelle Ankunftszeiten habe ich das Attribut von Gross bis klein sortiert und konnte so die linien_id herauslesen (719)
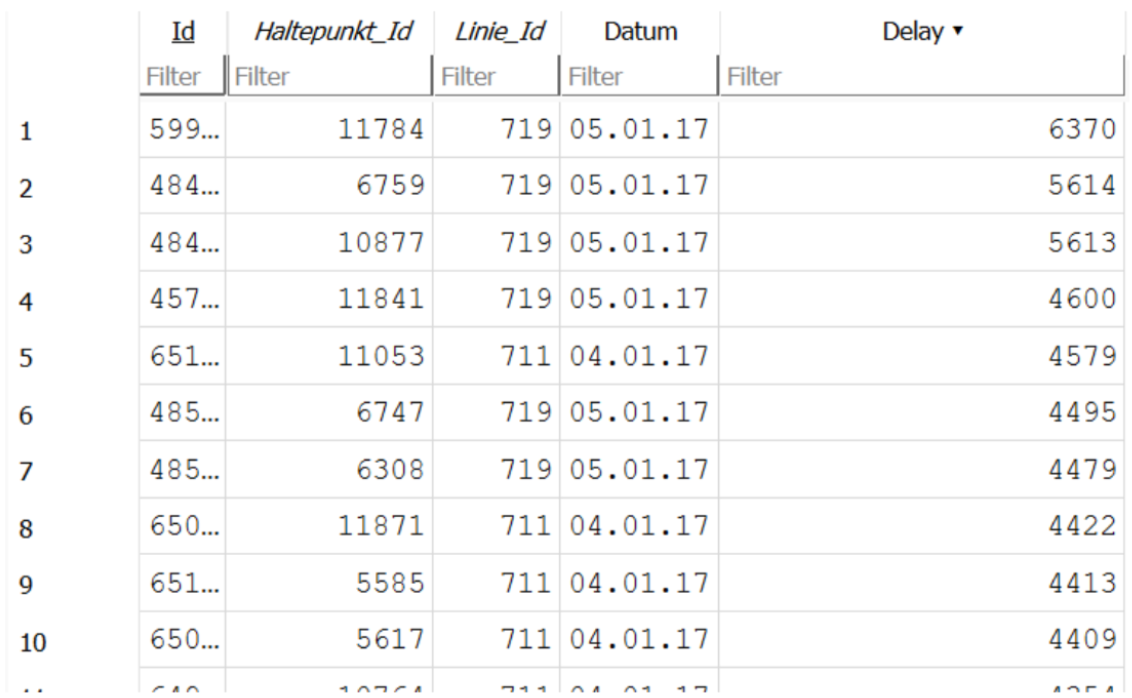
Lösung:
Bei der Ausgabe kann man die durchschnittliche Verspätung aller tage von 03.01.17 bis 07.01.17 herauslesen.
Berechnung

3.3.2¶
Zuverlässigste Linie an die ETH vom Bahnhof
Der Code:
SELECT
f.Nummer AS Linie,
ROUND(AVG(a.Delay), 2) AS Durchschnittliche_Verspaetung
FROM
Ankunftszeiten AS a
JOIN
Linie AS f ON a.Linie_Id = f.Id
WHERE
f.Nummer IN (6, 10) -- Filter für Linie 6 und 10
GROUP BY
f.Nummer
ORDER BY
Durchschnittliche_Verspaetung;
Ausgabe:
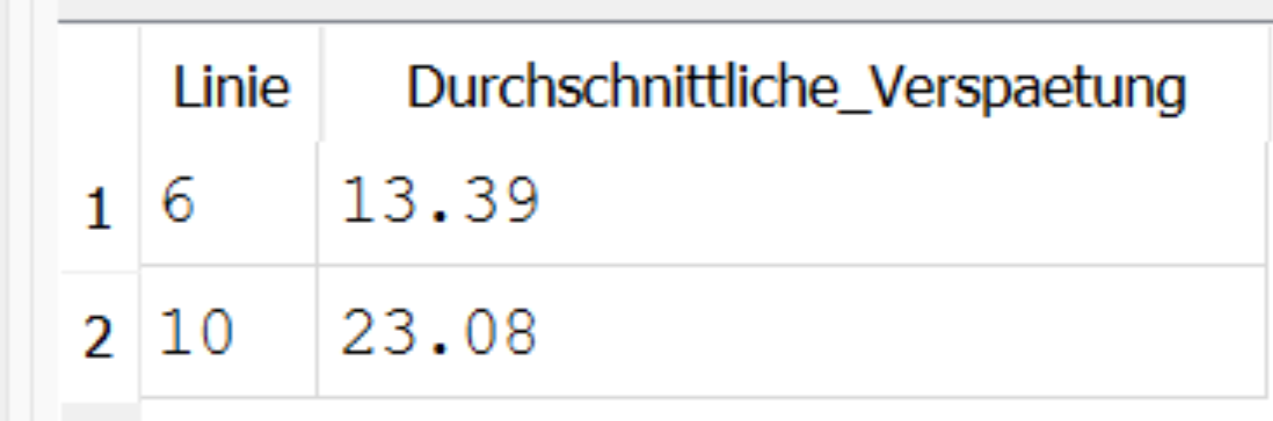
Die Linie 6 ist pünktlicher als die Linie 10
3.3.3¶
Analyse einer gegebenen SQL-Abfrage
Code auskommentiert:
SELECT
Linie.Nummer, -- Wählt die Nummer der Linie aus
AVG(Delay) AS Durchschnittliche_Verspaetung, -- Berechnet die durchschnittliche Verspätung und benennt die Spalte
COUNT(Linie.Id) AS Anzahl_Ankuenfte -- Zählt die Anzahl der Ankünfte und benennt die Spalte
FROM
Haltepunkt
JOIN
Haltestelle ON Haltepunkt.Haltestelle_Id = Haltestelle.Id -- Verbindet Haltepunkt und Haltestelle über Haltestelle_Id
JOIN
Ankunftszeiten ON Ankunftszeiten.Haltepunkt_Id = Haltepunkt.Id -- Verbindet Ankunftszeiten und Haltepunkt über Haltepunkt_Id
JOIN
Linie ON Linie.Id = Ankunftszeiten.Linie_Id -- Verbindet Linie und Ankunftszeiten über Linie_Id
WHERE
Haltestelle.Langname LIKE "%Bellevue%" -- Filtert die Haltestellen nach dem Namen "Bellevue"
AND Delay >= 0 -- Berücksichtigt nur Verspätungen, die größer oder gleich 0 sind
GROUP BY
Linie.Nummer -- Gruppiert die Ergebnisse nach der Liniennummer
ORDER BY
AVG(Delay) DESC; -- Sortiert die Ergebnisse nach der durchschnittlichen Verspätung in absteigender Reihenfolge
Dieser SQL-Code berechnet die durchschnittliche Verspätung und die Anzahl der Ankünfte für Linien bei der Haltestelle "Bellevue" und sortiert die Ergebnisse nach durchschnittlicher Verspätung:
SQL Murder-City¶
1. Identifizierung des Verdächtigen und seiner Anwesenheit zur fraglichen Zeit¶
Zunächst habe ich die Datenbank durchsucht, um festzustellen, wer zur relevanten Zeit am Tatort anwesend war. Dabei konnte ich herausfinden, dass Jeremy Bowers zum fraglichen Zeitpunkt im Fitnessstudio war. Die folgende Abfrage bestätigte seinen Check-in am 15. Januar 2020:
SELECT *
FROM get_fit_now_check_in
WHERE check_in_date = '2020-01-15'
AND membership_id = (
SELECT membership_id
FROM get_fit_now_member
WHERE person_id = (
SELECT id
FROM person
WHERE name = 'Jeremy Bowers'
)
);
2. Abrufen der Personendetails¶
Im nächsten Schritt habe ich detaillierte Informationen über Jeremy Bowers abgerufen, um seine Identität und seinen Hintergrund besser zu verstehen. Die folgende Abfrage gab mir alle relevanten persönlichen Daten:
Diese Informationen halfen dabei, seine Bewegungen und Aktivitäten genauer nachzuvollziehen.
3. Überprüfung des Alibis¶
Im dritten Schritt war es entscheidend, Jeremys Alibi zu prüfen und zu verifizieren, ob er zur fraglichen Zeit tatsächlich am angegebenen Ort war. Dazu habe ich sämtliche Check-ins im Fitnessstudio abgefragt:
SELECT *
FROM get_fit_now_check_in
WHERE membership_id = (
SELECT membership_id
FROM get_fit_now_member
WHERE person_id = (
SELECT id
FROM person
WHERE name = 'Jeremy Bowers'
)
);
4. Verbindung des Tatorts mit der verdächtigen Person¶
Es war wichtig, den Tatort und den Zeitpunkt des Verbrechens in den Kontext zu setzen. Die folgende Abfrage der Tatortdaten bestätigte, dass der Vorfall tatsächlich am 15. Januar 2020 stattfand:
Diese Erkenntnis half dabei, Jeremys Alibi und die Abfolge der Ereignisse abzugleichen.
5. Überprüfung der Aussagen von Jeremy Bowers¶
Um mögliche Widersprüche in Jeremys Aussagen zu erkennen, habe ich seine Interviews und die dazugehörigen Daten überprüft. Die folgende Abfrage gab Aufschluss über seine Interviews:
6. Fazit und Identifizierung des Täters¶
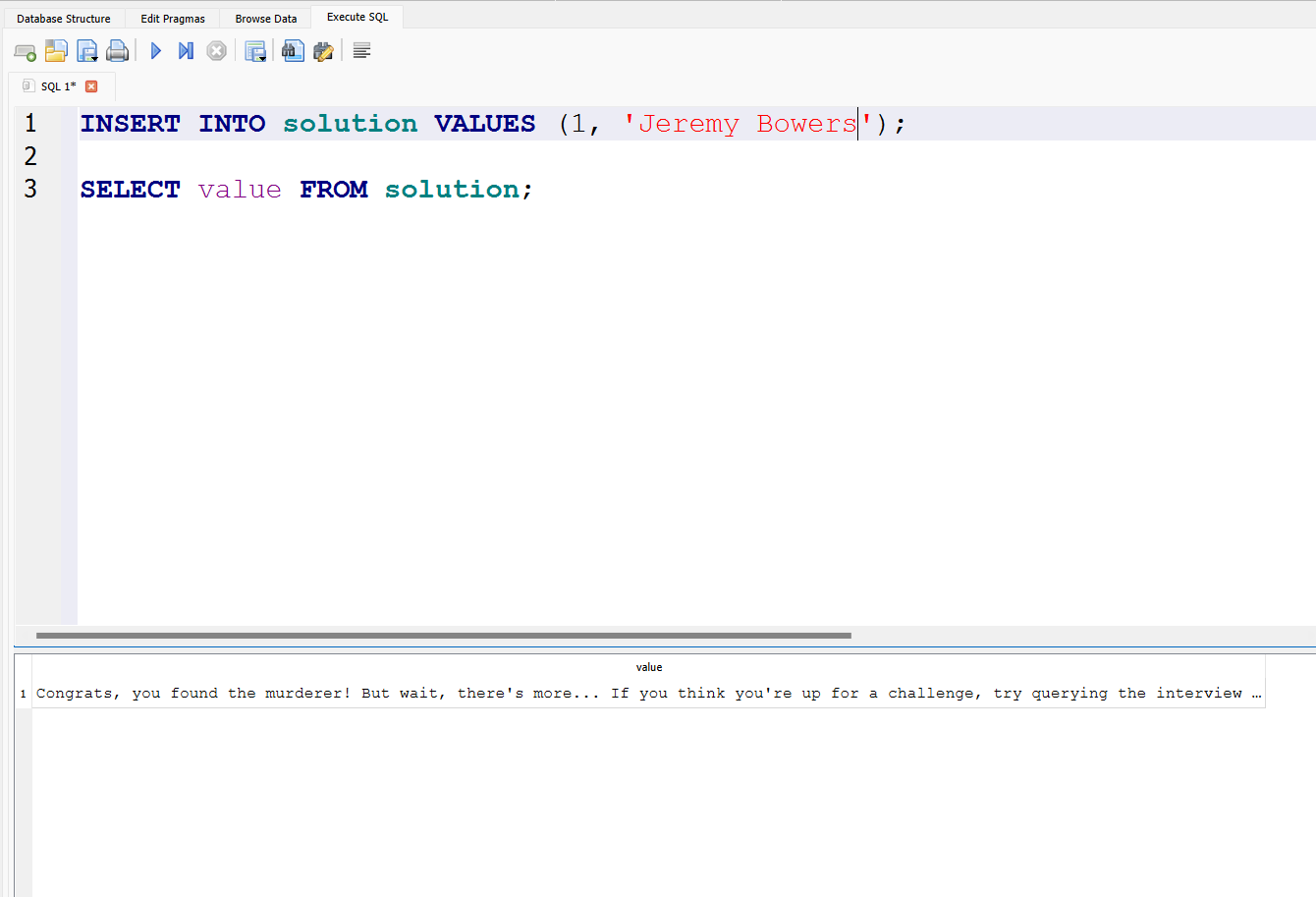
Die Kombination aller gesammelten Informationen und Analysen führte zu der Schlussfolgerung, dass Jeremy Bowers zur fraglichen Zeit im Fitnessstudio war. Dennoch konnte sein Alibi nicht zweifelsfrei bestätigt werden. Weiterführende Untersuchungen ergaben, dass er nicht die Wahrheit sagte. Aufgrund der vorliegenden Beweise wurde Jeremy Bowers schließlich als Hauptverdächtiger identifiziert.
der Code um zu überprüfen ob es der richtige ist:
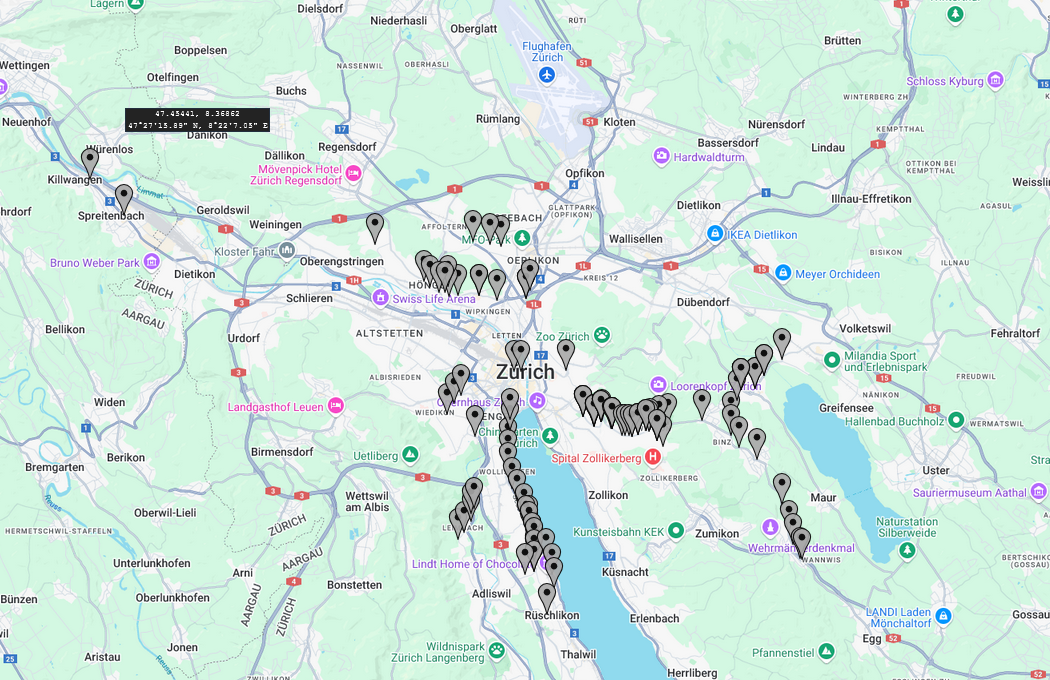
Grafische Darstellung:¶
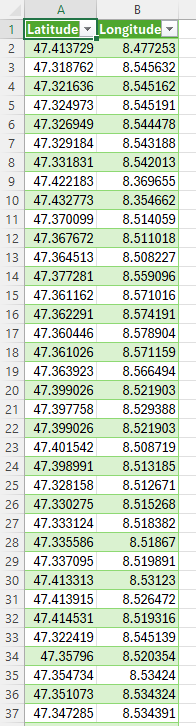
Wir haben aus der Liste mit folgendem Code die Daten exportiert:
SELECT Haltepunkt.Latitude, Haltepunkt.Longitude
FROM Haltepunkt
INNER JOIN Haltestelle ON Haltepunkt.Haltestelle_Id = Haltestelle.Id
INNER JOIN Ankunftszeiten ON Ankunftszeiten.Haltepunkt_Id = Haltepunkt.Id WHERE Ankunftszeiten.Delay > 1800;
Dann haben wir aus den Daten eine csv datei erstellt:
Danach sind wir auf die Website Map Maker gegeangen und haben dort eine grafische èbersicht gemacht: