M165 NoSQL Datenbanken | Block 01¶
Navigation¶
Note
23.11.2025, Tim Langenauer, V 2.0
Zusammenhänge darstellen¶
flowchart TD
%% =======================================
%% Hauptstruktur: Daten → Informationen → Wissen
%% =======================================
DATA["Daten<br/>• Rohmaterial<br/>• Zahlen, Buchstaben, Symbole"]
INFO["Informationen<br/>• Bedeutung<br/>• Zusammenhang"]
KNOW["Wissen<br/>• Verstehen<br/>• Anwenden"]
REPR["Repräsentation<br/>• Diagramme<br/>• Bilder<br/>• Tabellen"]
ABS["Abstraktion<br/>• Vereinfachung<br/>• Wesentliches"]
RED["Redundanz<br/>• Mehrfach vorhanden<br/>• Unnötig"]
%% =======================================
%% Strukturierung + Unterkategorien
%% =======================================
STRUCT["Datenstruktur<br/>• Tabelle, JSON, CSV<br/>• Graph, Baum, Stapel"]
STRUKTURIERT["strukturiert<br/>• Tabellen<br/>• Datenbanken<br/>• Banktransaktionen"]
SEMISTRUKT["semi-strukturiert<br/>• JSON<br/>• E-Mail"]
UNSTRUKT["unstrukturiert<br/>• Text<br/>• Bilder<br/>• Musik"]
%% =======================================
%% Erweiterte Fachbegriffe
%% =======================================
ANALYSE["Datenanalyse<br/>• Infos gewinnen"]
QUALITY["Datenqualität<br/>• Vollständigkeit<br/>• Konsistenz<br/>• Aktualität"]
MODEL["Datenmodellierung<br/>• Beziehungen<br/>• Tabellen + Diagramme"]
LITERACY["Data Literacy / Datenkompetenz<br/>• Lesen, Verstehen<br/>• Analysieren, Verwalten"]
STATS["Primär-/Sekundärstatistik<br/>• direkte Erhebung / Wiederverwendung"]
DDDO["DDD / DDO<br/>• Data Driven Decisions<br/>• Data Driven Organisations"]
DOMAINS["Domänen<br/>• Problemdomäne<br/>• IT-Domäne"]
%% =======================================
%% Beziehungen
%% =======================================
DATA -->|wird zu| INFO
INFO -->|führt zu| KNOW
DATA -->|wird dargestellt als| REPR
REPR -->|nutzt| ABS
DATA -->|kann enthalten| RED
DATA -->|wird strukturiert als| STRUCT
STRUCT -->|Kategorie| STRUKTURIERT
STRUCT -->|Kategorie| SEMISTRUKT
STRUCT -->|Kategorie| UNSTRUKT
STRUCT -->|nutzt| MODEL
DATA -->|wird analysiert durch| ANALYSE
ANALYSE -->|erzeugt| INFO
DATA -->|Qualität beeinflusst| QUALITY
LITERACY -->|befähigt Umgang mit| DATA
STATS -->|liefert| DATA
DDDO -->|nutzt| DATA
DOMAINS -->|liefert Kontext für| DATAFachbegriffe – Übersichtstabelle¶
| Fachbegriff | Kurze Erklärung | Beispiele / Attribute |
|---|---|---|
| Data Literacy / Datenkompetenz | Fähigkeit, Daten zu lesen, zu verstehen, zu analysieren und anzuwenden | Lesen, Verstehen, Analysieren, Verwalten |
| Daten | Rohmaterial ohne Kontext | Zahlen, Symbole, Messwerte |
| Informationen | Daten mit Bedeutung und Zusammenhang | Kontext, Auswertung |
| Wissen | Verstandene und angewendete Informationen | Erfahrung, Handlungskompetenz |
| Datenstruktur | Wie Daten organisiert sind | Tabelle, JSON, CSV, Graph |
| strukturiert | Stark regelbasiert aufgebaut | Tabellen, Datenbanken |
| semi-strukturiert | Teilweise strukturiert | JSON, XML, E-Mail |
| unstrukturiert | Ohne feste Struktur | Text, Bilder, Audio |
| Datenqualität | Eigenschaften guter Daten | Vollständigkeit, Konsistenz, Aktualität |
| Redundanz | Mehrfach vorhandene Daten | Dubletten, Konflikte |
| Reprasentation | Darstellung von Daten | Diagramme, Tabellen, Bilder |
| Abstraktion | Vereinfachung komplexer Inhalte | Fokus aufs Wesentliche |
| Datenanalyse | Aus Daten Informationen ableiten | Filtern, Berechnen, Vergleichen |
| Datenmodellierung | Beziehungen und Strukturen darstellen | ER-Diagramm, Tabellenmodell |
| Primärstatistik | Daten direkt fuer Analyse erhoben | Umfrage, Messung |
| Sekundärstatistik | Bereits vorhandene Daten wiederverwenden | Open-Data, Archivdaten |
| DDD / DDO | Entscheidungen / Organisationen basierend auf Daten | Data Driven Decisions, Data Driven Organisations |
| Domänen | Bereiche eines Projekts | Problemdomäne, IT-Domäne |
| Datenquelle | Ursprung der Daten | Sensor, API, Benutzer |
| Meta-Daten | Daten ueber Daten | Format, Autor, Datum |
| Datenpipeline | Ablauf der Datenverarbeitung | Erheben → Verarbeiten → Speichern |
| Datenverarbeitung | Verarbeitungsschritte | Filtern, Transformieren, Aggregieren |
| Begriff | Definition | Beispiel | Fokus |
|---|---|---|---|
| Daten | Unverarbeitete Rohwerte, Zeichen oder Symbole ohne Kontext. | 39 |
Beobachtung |
| Information | Daten, die durch Kontext eine Bedeutung erhalten haben. | „Die Person hat 39°C Fieber.“ |
Relevanz |
| Wissen | Verknüpfung von Informationen mit Erfahrung und Urteilsvermögen. | „Ab 39°C Fieber sollte man einen Arzt aufsuchen.“ |
Handeln |
Definition NoSQL¶
NoSQL ("Not only SQL") bezeichnet Datenbanken, die einen nicht-relationalen Ansatz verfolgen. Sie speichern Daten nicht in starren Tabellen, sondern in flexiblen Formaten.
- Verwendung: Sie werden dort eingesetzt, wo riesige Datenmengen (Big Data), unstrukturierte Daten (z. B. Social Media Posts) oder extrem hohe Zugriffsgeschwindigkeiten (Echtzeit-Apps) erforderlich sind.
Unterschied SQL und NoSQL¶
| Merkmal | Relationale Datenbanken (SQL) | NoSQL-Datenbanken |
|---|---|---|
| Speicherform | Tabellen mit festen Zeilen/Spalten | Dokumente, Key-Value, Graphen |
| Schema | Starr: Vorher festgelegt | Dynamisch: Flexibel anpassbar |
| Skalierung | Vertikal: Stärkerer Server | Horizontal: Mehr Server (Cluster) |
| Fokus | Datensicherheit & Konsistenz (ACID) | Geschwindigkeit & große Datenmengen |
| Abfrage | Strukturierte Sprache (SQL) | Datenbank-spezifisch |
| Einsatz | ERP, CRM, Bankwesen | Big Data, Echtzeit-Apps, Content-Management |
| Aspekt | Erklärung | Beispiel für mangelnde Qualität |
|---|---|---|
| Genauigkeit (Accuracy) | Die Daten müssen die Realität korrekt widerspiegeln. | Ein Geburtsdatum ist falsch in das System eingetippt worden. |
| Vollständigkeit (Completeness) | Alle erforderlichen Datenelemente müssen vorhanden sein. | In einer Kundendatenbank fehlen bei 30% der Einträge die E-Mail-Adressen. |
| Konsistenz (Consistency) | Daten dürfen sich in verschiedenen Systemen nicht widersprechen. | Ein Kunde ist in der Versandabteilung als "aktiv", in der Buchhaltung aber als "gelöscht" markiert. |
| Aktualität (Timeliness) | Die Daten müssen für den Zeitpunkt der Nutzung noch relevant und neu genug sein. | Eine Marketing-Kampagne nutzt Adressdaten, die bereits drei Jahre alt sind (viele Umzüge). |
| Merkmal | JSON | XML |
|---|---|---|
| Struktur | Datenorientiert (Key-Value) | Dokumentorientiert (Tags) |
| Syntax | Schlank { "id": 1 } |
Ausführlich <id>1</id> |
| Lesbarkeit | Sehr hoch (ähnlich wie Code) | Gut, aber durch Tags überladen |
| Datentypen | Unterstützt Arrays, Zahlen, Booleans | Alles wird als Text behandelt |
| Parsen | Sehr schnell (nativ in JS) | Langsamer (DOM-Baum-Erstellung) |
| Komplexität | Einfach | Hoch (unterstützt Schema/Namespaces) |
Herausforderungen NoSQL¶
| Bereich | Vorteile | Herausforderungen (Nachteile) |
|---|---|---|
| Skalierbarkeit | Horizontal: Einfaches Hinzufügen günstiger Server (Cluster). | Höherer Aufwand bei der Verwaltung großer Cluster. |
| Flexibilität | Schema-los: Datenstruktur kann jederzeit ohne Downtime geändert werden. | Fehlende Strukturvorgaben können zu "Daten-Wildwuchs" führen. |
| Performance | Extrem schnell bei einfachen Lese-/Schreibzugriffen und Big Data. | Langsam oder komplex bei tief verschachtelten Abfragen. |
| Datenintegrität | Optimiert für Hochverfügbarkeit. | Keine eingebauten ACID-Garantien (oft nur "Eventual Consistency"). |
| Abfragen | Spezialisierte Modelle (z. B. für Graphen oder Dokumente). | Kein einheitliches SQL; Joins müssen oft händisch programmiert werden. |
Denormalisierung¶
| Vorteile | Nachteile |
|---|---|
| Lese-Performance: Alle Daten für eine Ansicht werden mit einem einzigen Zugriff geladen (keine teuren Joins). | Datenredundanz: Informationen sind mehrfach vorhanden, was den Speicherbedarf erhöht. |
| Skalierbarkeit: Da Daten nicht über Servergrenzen hinweg verknüpft werden müssen, lässt sich das System leichter verteilen. | Update-Aufwand: Eine Änderung (z. B. Namensänderung eines Nutzers) muss an vielen Stellen gleichzeitig durchgeführt werden. |
| Einfachheit: Die Datenstruktur entspricht oft direkt den Objekten in der Applikationslogik. | Inkonsistenz-Risiko: Wenn ein Update fehlschlägt, sind die Datenbestände nicht mehr synchron. |
Rollen von Indizes¶
Indizes sind auch in NoSQL essenziell, um Suchanfragen zu beschleunigen, da sonst die gesamte Datenbank (Full Scan) durchsucht werden müsste.
-
Gemeinsamkeit: Beide nutzen meist B-Bäume oder Hash-Strukturen, um den Zugriffsweg zu verkürzen.
-
Unterschiede:
-
In SQL: Indizes sind oft sehr starr und beziehen sich auf vordefinierte Spalten.
-
In NoSQL: Es gibt oft spezialisierte Indizes für flexible Daten, wie z. B. Geospatial-Indizes (für Koordinaten), Volltext-Indizes oder Indizes auf Felder innerhalb von Arrays (Multikey-Indizes).
Wichtigste Befehle im Überblick:¶
| Phase | Befehl | Zweck / Wirkung |
|---|---|---|
| Start | show dbs |
Listet alle Datenbanken auf dem Server auf. |
| Start | use fitnessDB |
Wechselt zur Datenbank (erstellt sie automatisch beim ersten Speichern). |
| Start | db |
Zeigt den Namen der aktuell aktiven Datenbank an. |
| Struktur | db.createCollection("mitglieder") |
Erstellt explizit eine neue Sammlung (Collection). |
| Struktur | show collections |
Listet alle Sammlungen in der aktuellen Datenbank auf. |
| Erstellen | db.mitglieder.insertOne({ name: "Ali", alter: 25 }) |
Fügt ein einzelnes Dokument (Datensatz) hinzu. |
| Erstellen | db.mitglieder.insertMany([{...}, {...}]) |
Fügt mehrere Dokumente gleichzeitig als Liste hinzu. |
| Lesen | db.mitglieder.find() |
Zeigt alle Dokumente in der Sammlung an. |
| Lesen | db.mitglieder.find().pretty() |
Formatiert die JSON-Ausgabe für bessere Lesbarkeit. |
| Lesen | db.mitglieder.findOne({ _id: 1 }) |
Gibt exakt ein Dokument zurück, das dem Filter entspricht. |
| Lesen | db.mitglieder.find({ alter: { $gt: 18 } }) |
Filtert Dokumente (hier: Alter größer als 18). |
| Lesen | db.mitglieder.find().limit(5) |
Begrenzt die Ergebnismenge auf maximal 5 Dokumente. |
| Lesen | db.mitglieder.find().skip(10) |
Überspringt die ersten 10 Treffer (Paginierung). |
| Lesen | db.mitglieder.find().sort({ name: 1 }) |
Sortiert die Ergebnisse (1 = aufsteigend, -1 = absteigend). |
| Analyse | db.mitglieder.countDocuments({}) |
Gibt die Anzahl der Dokumente in der Sammlung zurück. |
| Analyse | db.mitglieder.distinct("stadt") |
Liefert alle eindeutigen Werte eines Feldes (z.B. alle Städte). |
| Update | db.mitglieder.updateOne({ id: 1 }, { $set: { aktiv: true } }) |
Ändert ein oder mehrere Felder eines Dokuments. |
| Update | db.mitglieder.updateMany({}, { $inc: { punkte: 10 } }) |
Erhöht einen Zahlenwert bei allen Dokumenten gleichzeitig. |
| Update | db.mitglieder.updateOne({ id: 1 }, { $push: { hobbys: "Yoga" } }) |
Fügt einen neuen Wert in ein bestehendes Array (Liste) ein. |
| Update | db.mitglieder.replaceOne({ id: 1 }, { name: "Neu" }) |
Ersetzt das gesamte Dokument (außer der ID). |
| Optimierung | db.mitglieder.createIndex({ name: 1 }) |
Erstellt einen Index, um die Suche nach "name" massiv zu beschleunigen. |
| Optimierung | db.mitglieder.getIndexes() |
Zeigt alle für diese Sammlung angelegten Indizes an. |
| Optimierung | db.mitglieder.find().explain("executionStats") |
Zeigt an, wie effektiv eine Abfrage (mit/ohne Index) war. |
| Löschen | db.mitglieder.deleteOne({ id: 1 }) |
Löscht das erste Dokument, das auf den Filter passt. |
| Löschen | db.mitglieder.deleteMany({ aktiv: false }) |
Löscht alle Dokumente, die das Kriterium erfüllen. |
| Löschen | db.mitglieder.dropIndex("name_1") |
Entfernt einen spezifischen Suchindex. |
| Löschen | db.mitglieder.drop() |
Löscht die komplette Sammlung inklusive aller Daten. |
| Löschen | db.dropDatabase() |
Löscht die gesamte Datenbank unwiderruflich. |
Ranking db-engines.com¶
Die populärsten
Datenbankmanagementsysteme
--
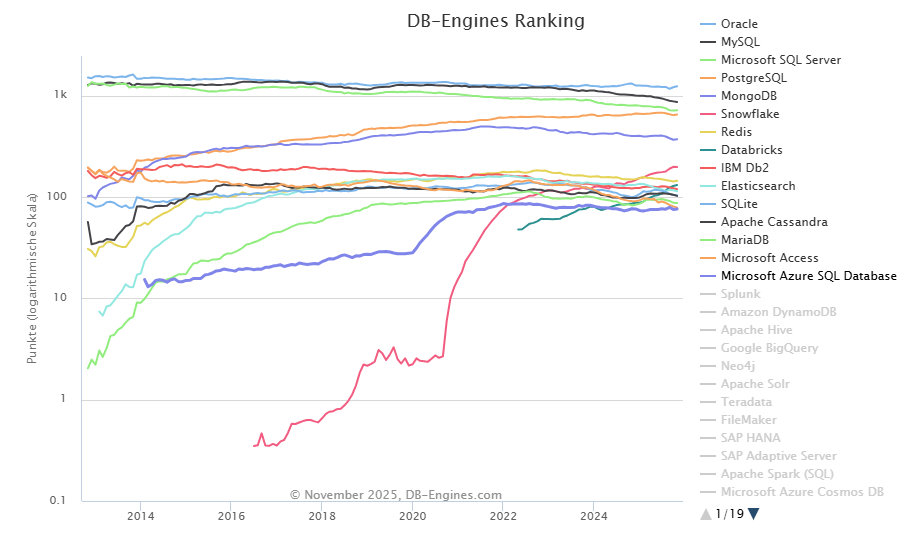
Relational DBMS¶
DB-Engines Ranking - die Rangliste der populärsten Relational DBMS
| Rang | Okt 2025 | Nov 2024 | DBMS | Datenbankmodell | Punkte Nov 2025 | Veränderung zu Okt 2025 | Veränderung zu Nov 2024 |
|---|---|---|---|---|---|---|---|
| 1. | 1 | 1 | Oracle | Relational, Multi-Model | 1239.78 | +27.01 | –77.23 |
| 2. | 2 | 2 | MySQL | Relational, Multi-Model | 865.82 | –13.84 | –151.98 |
| 3. | 3 | 3 | Microsoft SQL Server | Relational, Multi-Model | 718.87 | +3.82 | –80.94 |
| 4. | 4 | 4 | PostgreSQL | Relational, Multi-Model | 651.36 | +8.16 | –2.97 |
| 5. | 5 | 5 | MongoDB | Multi-Model (NoSQL, Dokument, KV, Graph-Funktionen) | 371.68 | +3.66 | –29.25 |
Key-Value Stores¶
DB-Engines Ranking - die Rangliste der populärsten Key-Value Stores
| Rang | Okt 2025 | Nov 2024 | DBMS | Datenbankmodell | Punkte Nov 2025 | Veränderung zu Okt 2025 | Veränderung zu Nov 2024 |
|---|---|---|---|---|---|---|---|
| 1. | 1 | 1 | MongoDB | Multi-Model | 371,68 | +3,66 | -29,25 |
| 2. | 2 | 2 | Redis | Key-Value, Multi-Model | 145,09 | +2,76 | -3,55 |
| 3. | 3 | 3 | Amazon DynamoDB | Multi-Model | 75,78 | -0,13 | +3,38 |
| 4. | 4 | 4 | Microsoft Azure Cosmos DB | Multi-Model | 22,55 | -0,16 | -1,40 |
| 5. | 5 | 5 | Memcached | Key-Value | 15,35 | -0,13 | -1,64 |
Document Stores¶
DB-Engines Ranking - die Rangliste der populärsten Document Stores
| Rang | Okt 2025 | Nov 2024 | DBMS | Datenbankmodell | Punkte Nov 2025 | Veränderung zu Okt 2025 | Veränderung zu Nov 2024 |
|---|---|---|---|---|---|---|---|
| 1. | 1 | 1 | MongoDB | Multi-Model | 371,68 | +3,66 | -29,25 |
| 2. | 2 | 2 | Databricks | Multi-Model | 131,50 | +2,70 | +45,04 |
| 3. | 3 | 3 | Amazon DynamoDB | Multi-Model | 75,78 | -0,13 | +3,38 |
| 4. | 4 | 4 | Microsoft Azure Cosmos DB | Multi-Model | 22,55 | -0,16 | -1,40 |
| 5. | 6 | 5 | Firebase Realtime Database | Document | 14,77 | -0,50 | +1,34 |
Time Series DBMS¶
DB-Engines Ranking - die Rangliste der populärsten Time Series DBMS
| Rang | Okt 2025 | Nov 2024 | DBMS | Datenbankmodell | Punkte Nov 2025 | Veränderung zu Okt 2025 | Veränderung zu Nov 2024 |
|---|---|---|---|---|---|---|---|
| 1. | 1 | 1 | MongoDB | Multi-Model | 371,68 | +3,66 | -29,25 |
| 2. | 2 | 2 | InfluxDB | Time Series, Multi-Model | 22,09 | +0,18 | +0,61 |
| 3. | 3 | 3 | Kdb | Multi-Model | 8,05 | +0,54 | +0,99 |
| 4. | 4 | 4 | Prometheus | Time Series | 7,92 | +0,44 | +1,00 |
| 5. | 5 | 5 | Graphite | Time Series | 4,78 | -0,13 | -0,13 |
Suchmaschinen¶
DB-Engines Ranking - die Rangliste der populärsten Suchmaschinen
| Rang | Okt 2025 | Nov 2024 | DBMS | Datenbankmodell | Punkte Nov 2025 | Veränderung zu Okt 2025 | Veränderung zu Nov 2024 |
|---|---|---|---|---|---|---|---|
| 1. | 1 | 1 | MongoDB | Multi-Model | 371,68 | +3,66 | -29,25 |
| 2. | 2 | 2 | Elasticsearch | Multi-Model | 113,97 | -2,69 | -17,67 |
| 3. | 3 | 3 | Splunk | Suchmaschine | 76,10 | +2,22 | -12,37 |
| 4. | 4 | 4 | Apache Solr | Suchmaschine, Multi-Model | 34,95 | -0,36 | +2,53 |
| 5. | 5 | 5 | OpenSearch | Multi-Model | 19,13 | -0,18 | +1,53 |
Graph DBMS¶
DB-Engines Ranking - die Rangliste der populärsten Graph DBMS
| Rang | Okt 2025 | Nov 2024 | DBMS | Datenbankmodell | Punkte Nov 2025 | Veränderung zu Okt 2025 | Veränderung zu Nov 2024 |
|---|---|---|---|---|---|---|---|
| 1. | 1 | 1 | Neo4j | Graph | 52,36 | -0,15 | +9,66 |
| 2. | 2 | 2 | Microsoft Azure Cosmos DB | Multi-Model | 22,55 | -0,16 | -1,40 |
| 3. | 3 | 3 | Aerospike | Multi-Model | 4,29 | -0,24 | -1,04 |
| 4. | 5 | 4 | ArangoDB | Multi-Model | 2,97 | +0,06 | -0,12 |
| 5. | 4 | 5 | Virtuoso | Multi-Model | 2,91 | +0,17 | -0,96 |
Erklärungen¶
| DBMS | Kurzbeschreibung | Kosten für User |
|---|---|---|
| Oracle | Sehr leistungsstarke Enterprise-SQL-Datenbank für grosse Unternehmen und kritische Systeme. | Sehr teuer (Lizenz + CPU-basierte Gebühren + Support). |
| MySQL | Sehr verbreitete SQL-Datenbank, besonders für Webprojekte. | Kostenlos (Community); Enterprise Edition kostenpflichtig. |
| Microsoft SQL Server | SQL-Datenbank im Microsoft-Ökosystem, viele Business-Features. | Express gratis; Standard/Enterprise kostenpflichtig pro CPU-Core. |
| PostgreSQL | Moderne, funktionsreiche Open-Source SQL-Datenbank mit vielen Erweiterungen (GIS, JSON). | Komplett kostenlos. |
| MongoDB | Flexibles Multi-Model-System (Dokumente, Key-Value, Graph). Ideal für moderne Apps. | Community Edition gratis; Atlas Cloud kostenpflichtig. |
| Redis | Super schneller In-Memory Key-Value Store, häufig als Cache genutzt. | Open-Source gratis; Enterprise/Cloud kostenpflichtig. |
| Amazon DynamoDB | AWS-verwalteter Key-Value/Dokumentenstore mit hoher Skalierbarkeit. | Pay-as-you-go (Requests, Speicher). |
| Azure Cosmos DB | Global verteilte Multi-Model Datenbank für Cloud-Anwendungen. | Pay-per-Request (RU/s), oft teuer bei grossen Loads. |
| Memcached | Sehr schneller, einfacher In-Memory Cache für Webserver. | Kostenlos (Open-Source). |
| Databricks | Data Lakehouse Plattform für Big Data, Streaming und Machine Learning. | Cloud-Abrechnung pro Compute-Unit (hochpreisig). |
| Firebase Realtime Database | Realtime-NoSQL-Datenbank für Mobile/Web, ideal für Live-Daten. | Günstiges Pay-as-you-go Modell. |
| InfluxDB | Spezialisiert auf Zeitreihen (Metriken, IoT, Sensoren). | Open-Source gratis; Enterprise/Cloud kostenpflichtig. |
| Kdb | Ultra-schnelle Time-Series DB, besonders im Finanzhandel. | Sehr teuer (Enterprise Lizenz). |
| Prometheus | Monitoring- und Metriken-Datenbank aus der Cloud-Welt. | Komplett kostenlos (Open-Source). |
| Graphite | Einfaches, bewährtes Time-Series System für Monitoring. | Kostenlos (Open-Source). |
| Elasticsearch | Such- und Analytics-Engine für Logs, Volltext und Observability. | Basis Open-Source; Enterprise/Cloud kostenpflichtig. |
| Splunk | Premium-Log-Analyse & Security Intelligence Plattform. | Sehr teuer (Preis nach ingestierter Datenmenge). |
| Apache Solr | Open-Source Suchmaschine für Volltext, basiert auf Lucene. | Kostenlos. |
| OpenSearch | Open-Source Suchmaschine, Elasticsearch-kompatibel. | Kostenlos; Managed Cloud Version kostenpflichtig. |
| Neo4j | Marktführer unter den Graph-Datenbanken (Beziehungen, Netzwerke). | Community gratis; Enterprise kostenpflichtig. |
| Aerospike | Hoch performante Multi-Model Datenbank für Realtime-Anwendungen. | Open-Source Basis gratis; Enterprise Lizenz teuer. |
| ArangoDB | Multi-Model DB (Dokument, Graph, Key-Value) in einer Engine. | Open-Source gratis; Enterprise Edition kostenpflichtig. |
| Virtuoso | Hybrid-DBMS für SQL + Graph (RDF). | Open-Source Version gratis; Enterprise Version kostet. |
| Typ | Bester Anwendungsfall | Beispiel-Szenario |
|---|---|---|
| Key-Value | Extrem schneller Zugriff auf einfache Daten. | Session-Management (Login-Status), Warenkörbe. |
| Document | Komplexe Daten mit variabler Struktur. | Content-Management (Blogs), Nutzerprofile, E-Commerce. |
| Column-Store | Analyse riesiger Datenmengen (Big Data). | Log-Daten-Analyse, Zeitreihen, IoT-Sensordaten. |
| Graph | Daten mit stark vernetzten Beziehungen. | Soziale Netzwerke, Empfehlungs-Engines, Betrugserkennung. |
Typen von NoSQL Datenbanken¶
| Typ | Bester Anwendungsfall | Beispiel-Szenario |
|---|---|---|
| Key-Value | Extrem schneller Zugriff auf einfache Daten. | Session-Management (Login-Status), Warenkörbe. |
| Document | Komplexe Daten mit variabler Struktur. | Content-Management (Blogs), Nutzerprofile, E-Commerce. |
| Column-Store | Analyse riesiger Datenmengen (Big Data). | Log-Daten-Analyse, Zeitreihen, IoT-Sensordaten. |
| Graph | Daten mit stark vernetzten Beziehungen. | Soziale Netzwerke, Empfehlungs-Engines, Betrugserkennung. |
Gruppenarbeit¶
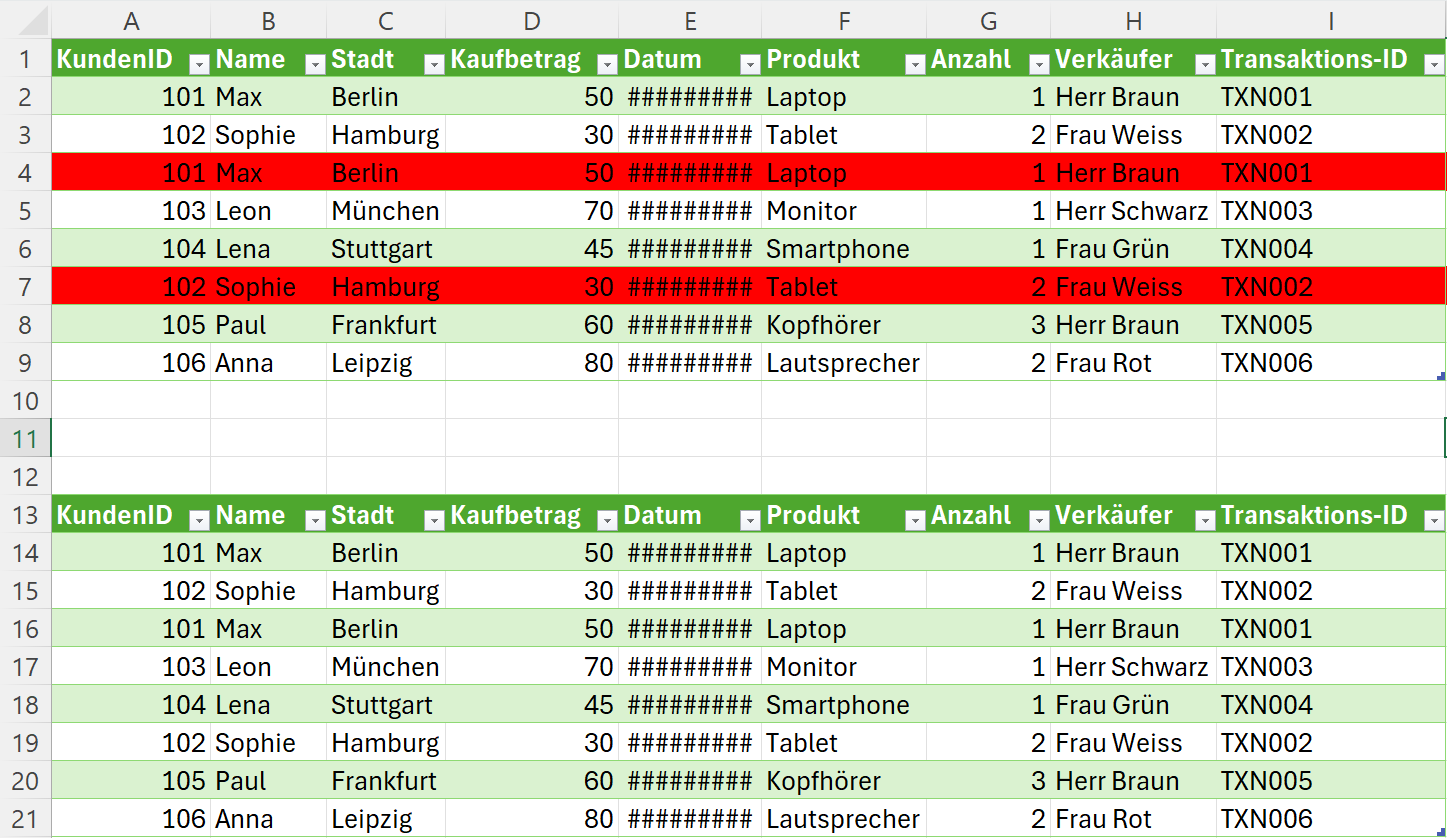
Tim: Was ist eine CSV Datei?
Karel: CSV Datei in Excel importieren?
Florin: Erklärung der beiden Doppelten Einträgen
Philipp: Erklärung wieso Problematisch mit Transaktions-ID
Jonas: Fazit
Tim – Was ist eine CSV-Datei?¶
Definition CSV
CSV bedeutet Comma Separated Values – ein einfaches Textformat für tabellarische Daten.
Eine CSV-Datei ist ein universelles, sehr stabiles Austauschformat. Jede Zeile ist ein Datensatz, Spalten werden durch Kommas getrennt.
Karel – CSV-Datei in Excel importieren¶
Zum Importieren öffnet man Excel → Daten → Aus Text/CSV.
Dort wählt man die Datei aus, und Excel erkennt automatisch die Spalten.
Man kann auswählen, welches Trennzeichen benutzt wurde (z. B. Komma oder Semikolon).
Danach kann man die Tabelle sortieren, filtern oder bearbeiten wie jede normale Excel-Tabelle.
Florin – Erklärung der doppelten Einträge¶
In unserer Datei sieht man z. B.:
- KundeID 101, Max, Berlin kommt zweimal vor
- KundeID 102, Sophie, Hamburg kommt ebenfalls zweimal vor
- Die Daten (Kaufbetrag, Datum, Produkt) sind bei den Duplikaten identisch
Das sind Redundanzen – also doppelte Daten, die eigentlich nur einmal vorkommen sollten.
Solche Duplikate sind problematisch, weil:
- Auswertungen verfälscht werden (z. B. Umsätze doppelt gezählt)
- Speicher verschwendet wird
- Fehler entstehen können, wenn man einen Eintrag ändert und den doppelten vergisst
Philipp – Wieso problematisch mit der Transaktions-ID¶
Jede Transaktion sollte eine eindeutige Transaktions-ID haben, z. B. TXN001.
In unserer Datei kommt TXN001 aber zweimal vor – bei Max am gleichen Datum und gleichen Produkt.
Das ist ein Problem, weil:
- Eine Transaktion nur einmal vorkommen darf
- Systeme wie Datenbanken oder Shops sonst nicht unterscheiden können:
→ War es wirklich zweimal derselbe Kauf?
→ Oder wurde der Datensatz einfach kopiert? - Man kann keine eindeutigen Nachweise erstellen (Rechnungen, Retouren, Garantie usw.)
Kurz: Doppelte Transaktions-IDs zerstören die Datenqualität.
Jonas – Fazit¶
CSV-Dateien sind ein einfaches, universelles Format – ideal für Datenaustausch.
Aber wie man bei unserem Beispiel sieht, müssen Daten sauber, eindeutig und ohne Duplikate sein.
Sonst entstehen Fehler bei Auswertungen, Analysen und automatischen Systemen.
Saubere Daten bedeuten: bessere Qualität, weniger Probleme, zuverlässige Ergebnisse.