Block 03 | Modul 106¶
Activity 2¶
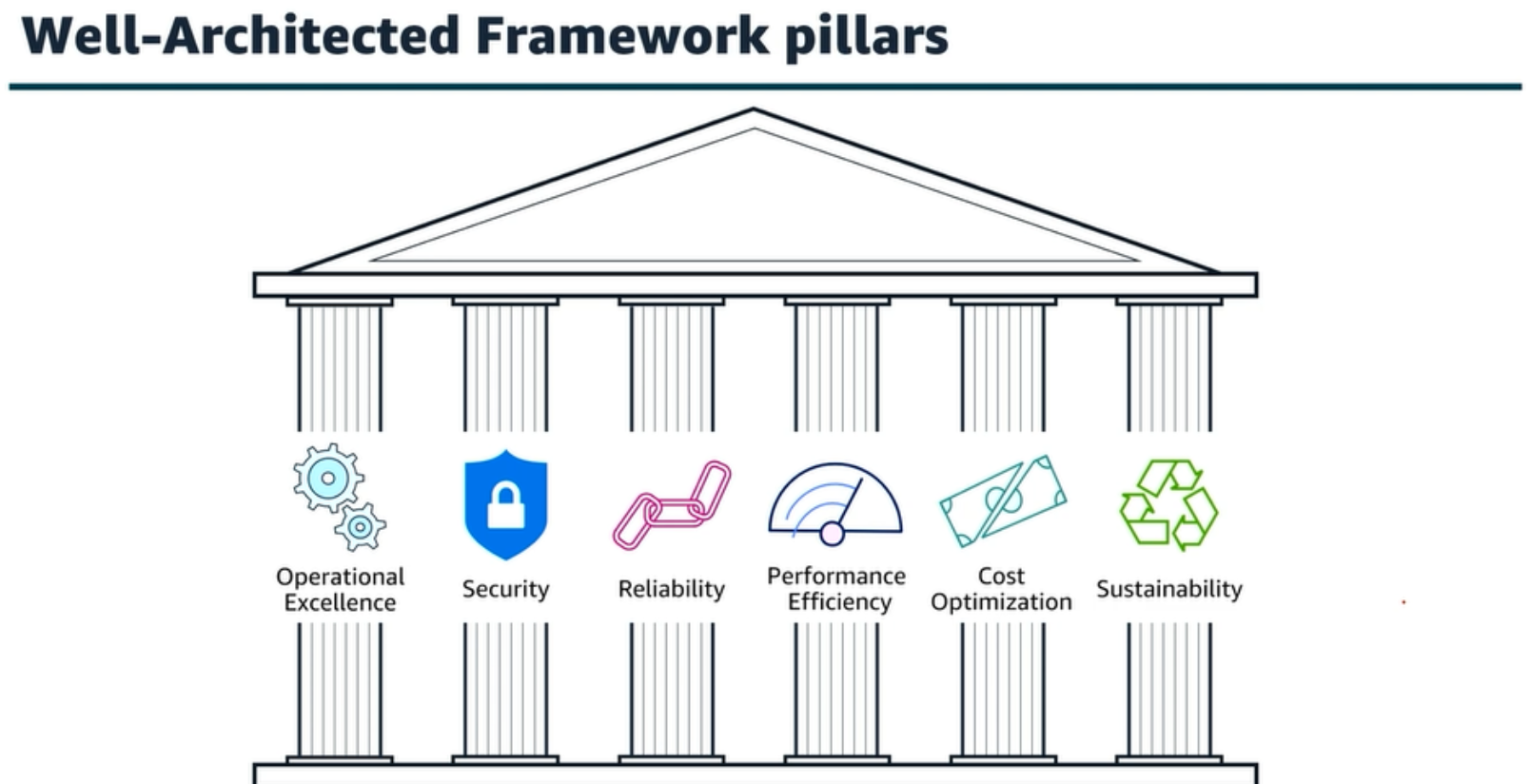
| Säule (englisch) | Best Practice (Designprinzip & Beschreibung) | Datencharakteristik (V) | Quelle / URL |
|---|---|---|---|
| Operational Excellence | 1 – Zustand der Analyseanwendung überwachen: Monitoring und Alarme einrichten, um Probleme früh zu erkennen und schnell reagieren zu können. | Velocity | Operational Excellence |
| Security | 3 – Datenplattform für Governance & Compliance gestalten: Datenplattform so aufbauen, dass Datenschutz und Zugriffskontrolle gewährleistet sind. | Veracity | Security |
| Reliability | 6 – Analyse-Workloads resilient gestalten: Redundanz und automatisches Failover nutzen, um Ausfälle abzufangen und Datenzugriff zu sichern. | Volume | Reliability |
| Performance Efficiency | 8 – Beste Compute-Lösung wählen: Compute-Optionen vergleichen und die wählen, die für verschiedene Datentypen optimale Leistung bringt. | Variety | Performance Efficiency |
| Cost Optimization | 11 – Kosteneffiziente Lösungen je nach Nutzung wählen: Analyse der Nutzung, um passende Compute- und Speicherlösungen mit gutem Preis-Leistungs-Verhältnis zu wählen. | Value | Cost Optimization |
Modul 5 Zusammenfassung¶
1. Cloud-Sicherheitsüberblick¶
Grundlagen der Sicherheit in Cloud-Umgebungen.
Kernaspekte:
-
Identitäts- und Zugriffsmanagement (IAM): Genaue Regelung, wer welche Aktionen durchführen darf (z. B. Administrator darf EC2-Instanzen starten, Entwickler nur auf bestimmte Ressourcen zugreifen).
-
Datenverschlüsselung: Schutz sensibler Informationen durch Verschlüsselung, etwa mit AWS KMS zur Verwaltung von Schlüsseln.
-
Netzwerkschutz: Einsatz von Sicherheitsgruppen und Firewalls zur Begrenzung des Netzwerkzugriffs (z. B. Webserver ist öffentlich, Datenbank bleibt intern).
Beispiel:
Ein Entwickler benötigt Zugriff auf bestimmte S3-Dateien, bekommt jedoch ausschließlich Leseberechtigung. Die Daten sind verschlüsselt und nur für autorisierte Nutzer zugänglich.
2. Sicherheit bei Analyse-Workloads¶
Sicherer Umgang mit Plattformen für Datenanalysen wie Data Lakes oder Warehouses.
Wichtige Aspekte:
-
Datenschutz: Speicherung sensibler Daten stets in verschlüsselter Form.
-
Feingranulare Zugriffsrechte: Differenzierter Zugriff auf Daten, z. B. nur auf bestimmte Spalten.
-
Audit-Logs: Erfassung sämtlicher Datenzugriffe (z. B. via AWS CloudTrail).
Beispiel:
Ein Unternehmen wertet Kundendaten in Amazon Redshift aus. Kreditkartendaten sind verschlüsselt gespeichert. Nur ausgewählte Analysten dürfen auf anonymisierte Informationen zugreifen. Alle Zugriffe werden protokolliert.
3. Sicherheit im Bereich Machine Learning¶
Sicherung von ML-Systemen und -Daten.
Wichtige Punkte:
-
Modellzugriff schützen: Zugriff auf ML-Modelle gezielt beschränken.
-
Integrität der Trainingsdaten: Manipulation verhindern.
-
Sicheres Deployment: Nur autorisierte Anwendungen dürfen Modelle nutzen.
Beispiel:
Ein Kreditwürdigkeitsmodell nutzt verschlüsselte Trainingsdaten, gespeichert in S3. Nur Data Scientists können darauf zugreifen. Das Modell wird nur über authentifizierte Schnittstellen abgefragt.
4. Überblick zum Skalieren¶
Grundprinzipien des Skalierens von IT-Systemen.
Zentrale Aspekte:
-
Vertikale Skalierung: Aufrüstung einzelner Server (z. B. mehr RAM oder CPU).
-
Horizontale Skalierung: Einsatz mehrerer Server zur Lastverteilung.
-
Automatische Skalierung: Ressourcen passen sich automatisch der Nachfrage an (z. B. mit AWS Auto Scaling).
Beispiel:
Vor Weihnachten steigen die Zugriffszahlen im Onlinehandel. AWS startet automatisch zusätzliche Instanzen, um die Last zu bewältigen.
5. Aufbau skalierbarer Infrastruktur¶
Wie man mit AWS eine skalierbare Umgebung erstellt.
Wichtige Konzepte:
-
Auto Scaling Groups: Automatische Bereitstellung neuer Instanzen bei hoher Last.
-
Elastic Load Balancer (ELB): Intelligente Verteilung eingehender Anfragen auf mehrere Server.
-
Verwaltete Dienste: AWS übernimmt Skalierung und Wartung (z. B. DynamoDB, RDS).
Beispiel:
Netflix nutzt AWS, um bei hoher Nachfrage automatisch Server zu starten und die Last gleichmäßig zu verteilen.
6. Entwicklung skalierbarer Komponenten¶
Design von Anwendungen mit Blick auf Skalierbarkeit und Flexibilität.
Wichtige Prinzipien:
-
Entkoppelte Komponenten: Dienste arbeiten unabhängig und skalieren individuell.
-
Nachrichtenwarteschlangen: Systeme wie Amazon SQS ermöglichen asynchrone Verarbeitung.
-
Serverlose Architekturen: Automatische Skalierung durch AWS Lambda, ohne Serverbetrieb.
Beispiel:
Ein Bestellsystem verwendet Amazon SQS. Der Webserver leitet Bestellungen in eine Warteschlange. Die Backend-Systeme verarbeiten sie unabhängig und skalierbar weiter.
Modul 6 Zusammenfassung¶
1. Vergleich von ETL und ELT¶
-
ETL (Extract, Transform, Load):
Daten werden aus Quellen gezogen, direkt verarbeitet (z. B. bereinigt oder formatiert) und danach in das Zielsystem geladen.
Vorteile: Schnellere Analyse durch vorbereitete Daten.
Nachteil: Änderungen sind schwerer umzusetzen, da Transformation bereits vor dem Laden erfolgt. -
ELT (Extract, Load, Transform):
Die Daten werden direkt in das Zielsystem übertragen und dort erst verarbeitet.
Vorteile: Hohe Flexibilität und Skalierbarkeit, vor allem bei großen Datenmengen.
Nachteil: Abfragen können langsamer sein; Rohdaten müssen effizient verwaltet werden.
Beispiel:
ETL eignet sich gut für stabile und strukturierte Systeme wie klassische Datenbanken.
ELT ist ideal für moderne Plattformen wie Data Lakes, die viele unstrukturierte Daten aufnehmen.
2. Einführung in Data Wrangling¶
Unter "Data Wrangling" versteht man das Aufbereiten und Umformen von Rohdaten, um sie analysierbar zu machen.
Warum notwendig? Rohdaten sind oft fehlerhaft, inkonsistent oder unvollständig.
Ziel: Die Datenqualität erhöhen und die Daten fit für die Analyse machen.
3. Data Discovery¶
Erster Schritt in der Datenanalyse: Verstehen, welche Daten vorhanden sind und wie sie beschaffen sind.
Fragen: Welche Daten stehen zur Verfügung? Gibt es Lücken? Sind sie brauchbar?
Methoden: Statistische Verfahren, manuelle Durchsicht oder automatisierte Tools.
Beispiel:
Vor einer Werbeaktion wird geprüft, ob Kundendaten vollständig und korrekt vorhanden sind.
4. Strukturierung von Daten¶
Unstrukturierte oder rohe Informationen werden in ein klares Schema überführt.
Warum wichtig? Nur strukturierte Daten lassen sich effizient abfragen und analysieren.
Vorgehen: Anwendung von Normalisierung, Aufbau relationaler Tabellen oder Definition von Datenmodellen.
Beispiel:
Daten aus mehreren CSV-Dateien werden in eine relationale Datenbank übertragen.
5. Datenbereinigung (Data Cleaning)¶
Säubern von fehlerhaften, unvollständigen oder doppelten Einträgen.
Typische Maßnahmen: Duplikate entfernen, unplausible Werte korrigieren, fehlende Daten ergänzen.
Beispiel:
Kundenprofile mit doppelten Einträgen werden zusammengeführt, ungültige E-Mail-Adressen korrigiert.
6. Datenanreicherung (Data Enrichment)¶
Bestehende Datensätze werden durch zusätzliche Informationen ergänzt.
Nutzen: Bessere Entscheidungsgrundlage durch kontextbezogene Daten.
Beispiele: Anreicherung durch externe Quellen, Standortdaten, demografische Merkmale.
Beispiel:
Kundendaten werden um GPS-Koordinaten ergänzt, um geografische Trends zu erkennen.
7. Datenvalidierung¶
Prüfung der Daten auf Korrektheit, Konsistenz und Sinnhaftigkeit.
Warum? Damit Analyseergebnisse vertrauenswürdig und belastbar sind.
Methoden: Prüfregeln, Grenzwertüberwachung, Abgleich mit Referenzdaten.
Beispiel:
Ein System erkennt automatisch, wenn Umsatzwerte negativ sind, und markiert sie als fehlerhaft.
8. Datenbereitstellung (Data Publishing)¶
Die final aufbereiteten Daten werden für Benutzer oder Systeme zur Verfügung gestellt.
Ziel: Einfache und transparente Nutzung der Daten.
Formate: Dashboards, automatisierte Berichte, APIs.
Beispiel:
Ein Dashboard zeigt täglich aktualisierte Verkaufszahlen an, auf die alle Analysten zugreifen können.
Die 5 Vs von Daten¶
Volume (Datenmenge)
– Beschreibt die riesige Menge an Daten, die täglich erzeugt wird (z. B. durch Sensoren, soziale Medien, Transaktionen). – Grosse Datenmengen erfordern skalierbare Speicher- und Verarbeitungslösungen.
Velocity (Geschwindigkeit) – Bezieht sich auf die Geschwindigkeit, mit der Daten erzeugt, übertragen und verarbeitet werden. – Beispiele: Live-Streaming, Echtzeit-Analysen, IoT-Datenströme.
Variety (Vielfalt) – Daten kommen in verschiedenen Formaten: strukturiert (z. B. Datenbanken), semi-strukturiert (z. B. JSON, XML) oder unstrukturiert (z. B. Videos, Texte, Bilder). – Systeme müssen mit all diesen Typen umgehen können.
Veracity (Zuverlässigkeit) – Beschreibt die Qualität und Vertrauenswürdigkeit der Daten. – Fehlerhafte oder unvollständige Daten können zu falschen Entscheidungen führen.
Value (Wert) – Der Nutzen, den ein Unternehmen aus den Daten ziehen kann. – Daten sind nur dann wertvoll, wenn sie sinnvoll analysiert und verwendet werden
Wie beeinflussen sich Volumen und Geschwindigkeit einer Datenpipeline?¶
-
Je grösser das Volumen, desto mehr Speicher- und Rechenleistung braucht die Pipeline.
-
Je höher die Geschwindigkeit (Velocity), desto schneller muss die Pipeline arbeiten – mit möglichst geringer Verzögerung (Latenz).
-
Kombinationseffekt: Hohe Geschwindigkeit + hohes Volumen stellt grosse Anforderungen an die Infrastruktur. Es braucht leistungsfähige Netzwerke, parallele Verarbeitung (z. B. mit Apache Spark) und skalierbare Cloud-Ressourcen (z. B. AWS Kinesis, Lambda).
Analyse: Hochfrequenzhandel an der Börse – Volumen und Geschwindigkeit¶
Beim Hochfrequenzhandel entstehen pro Sekunde tausende bis Millionen von Transaktionen, die innerhalb von Millisekunden verarbeitet und analysiert werden müssen.
-
Volume: Sehr hoch – grosse Mengen an Echtzeitdaten (z. B. Kursdaten, Orders, Nachrichten).
-
Velocity: Extrem hoch – Daten müssen nahezu in Echtzeit verarbeitet werden, da Bruchteile von Sekunden über Gewinn oder Verlust entscheiden.
Fazit: Die Datenpipeline in diesem Kontext muss hochperformant, skalierbar und extrem schnell sein.
AWS Well-Architected Framework and Lenses¶
- Das Well-Architected Framework bietet Best Practices und Designleitfäden auf sechs Säulen
- Die Well-Architected Framework-Objektive erweitern die Leitlinien, sodass sie sich auf bestimmte Bereiche konzentrieren
- Die Data Analytics Lens bietet Orientierungshilfen, die bei Entwurfsentscheidungen in Bezug auf die einzelnen Datenelemente (Volumen, Geschwindigkeit, Vielfalt, Richtigkeit und Wert) helfen.
The evolution of data architectures¶
- Datenspeicher und Architekturen wurden weiterentwickelt, um sich an die steigenden Anforderungen an Datenvolumen, Vielfalt und Geschwindigkeit anzupassen.
- Moderne Datenarchitekturen verwenden weiterhin verschiedene Arten von Datenspeichern, um unterschiedlichen Anwendungsfällen gerecht zu werden.
- Das Ziel der modernen Architektur besteht darin, unterschiedliche Quellen zu vereinheitlichen, um eine einzige Informationsquelle bereitzustellen.
Modern data architecture pipeline: Ingestion and storage¶
- Die moderne AWS-Datenarchitektur verwendet speziell entwickelte Tools, um Daten auf der Grundlage von Datenmerkmalen aufzunehmen.
- Die Speicherebene verwendet Amazon Redshift als Data Warehouse und Amazon S3 für ihren Data Lake.
- Der Amazon S3-Datensee verwendet Präfixe oder einzelne Buckets als Zonen, um Daten in verschiedenen Zuständen zu organisieren, von der ersten Speichern bis zur Kuratierung.
- AWS Glue und Lake Formation werden in einer Katalogebene zum Speichern von Metadaten verwendet.
- Mit dem Katalog kann Amazon Redshift Spectrum Daten in Amazon S3 direkt abfragen.
Modern data architecture pipeline: Processing and consumption¶
- Komponenten in der Verarbeitungsschicht sind dafür verantwortlich, Daten in einen verarbeitbaren Zustand umzuwandeln.
- Die Verarbeitungsebene unterstützt drei Arten der Verarbeitung: SQL-basiertes ELT, Big-Data-Verarbeitung und ETL nahezu in Echtzeit.
- Die Nutzungsebene bietet einheitliche Schnittstellen für den Zugriff auf alle Daten und Metadaten in der Speicherebene.
- Die Verbrauchsebene unterstützt drei Analysemethoden: interaktive SQL-Abfragen, BI-Dashboards und ML.
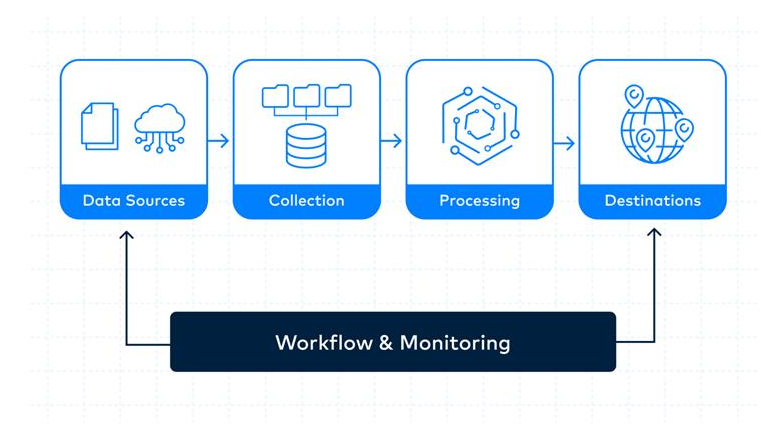
Streaming analytics pipeline¶
- Streaming-Analysen umfassen Produzenten und Konsumenten.
- Ein Stream bietet temporären Speicher, um eingehende Daten in Echtzeit zu verarbeiten.
- Die Ergebnisse der Streaming-Analysen können auch auf nachgelagerten Zielen gespeichert werden.
Sicherheit (Securing)¶
Massnahmen bei verdächtigen Aktivitäten:
-
Überwachung und Alarmierung:
Nutzung von CloudWatch Events zur Erfassung und Überwachung von sicherheitsrelevanten Ereignissen. -
Zugriffskontrolle:
Einsatz von IAM-Rollen und -Policies zur restriktiven Steuerung von Berechtigungen.
Weitere mögliche Massnahmen: Verschlüsselung von Daten, Einsatz von Security Groups, Web Application Firewall (WAF), GuardDuty.
Skalierbarkeit (Scaling)¶
Massnahmen zur Sicherstellung der Skalierbarkeit:
-
Auto Scaling:
Automatisches Skalieren von Ressourcen mit Application Auto Scaling je nach Last. -
Einsatz skalierbarer Services:
Nutzung von AWS-Services wie Kinesis Data Streams, Kinesis Data Analytics, Amazon S3 und Amazon Redshift, die grosse Datenvolumen verarbeiten können.
Stream Processing Pipeline (Beispielaufbau)¶
-
Data Sources: Kontinuierliche Datenströme (z. B. Logs, Events)
-
Ingestion & Producers: CloudWatch Events zur Erfassung der eingehenden Daten.
-
Stream Storage: Speicherung in Kinesis Data Streams.
-
Stream Processing & Consumers: Verarbeitung der Daten mit Kinesis Data Analytics.
-
Downstream Destinations: Speicherung der Ergebnisse in Amazon S3 oder Amazon Redshift.
ETL-Dienst (AWS Glue)¶
-
AWS Glue ist ein ETL-Service (Extract, Transform, Load), der Daten aus verschiedenen Quellen extrahiert, transformiert und in ein Zielsystem lädt.
-
Glue automatisiert viele Schritte des ETL-Prozesses (z. B. Schema-Erkennung, Job-Orchestrierung).
Vorteile ETL vs. ELT¶
ETL (Extract → Transform → Load):
-
Transformation findet vor dem Laden statt.
-
Daten werden bereinigt und strukturiert, bevor sie gespeichert werden.
-
Vorteile:
-
Datenqualität bereits beim Speichern hoch.
-
Geringere Anforderungen an das Zielsystem.
-
Gut für klassische DWH-Systeme.
ELT (Extract → Load → Transform):
-
Rohdaten werden direkt ins Zielsystem geladen.
-
Transformation erfolgt nach dem Laden.
-
Vorteile:
-
Flexibler bei grossen Datenmengen.
-
Zielsysteme (z. B. Cloud DWH) übernehmen die Rechenlast.
-
Bessere Performance bei moderner Cloud-Architektur.
Data Wrangling¶
-
Datenaufbereitung aus unterschiedlichen Quellen.
-
Ziel: Daten in ein einheitliches, analysierbares Format bringen.
Schritte im Data Wrangling¶
-
Cleaning: Fehlerhafte, doppelte oder unvollständige Daten korrigieren oder entfernen.
-
Structuring: Daten in die gewünschte Struktur bringen (z. B. Tabellenformate).
-
Enriching: Zusätzliche Informationen ergänzen (z. B. Datenquellen kombinieren).
-
Validating: Überprüfen der Datenqualität und Korrektheit.